写在前面
随便学学 llvm 代码混淆,顺便做个毕设,水几篇文章就当做做笔记
基本块分割
基本块分割即将一个基本块分割为等价的若干个基本块,在分割后的基本块之间加上无条件跳转。
基本块分割不能算是混淆,但是可以提高某些代码混淆的混淆效果。
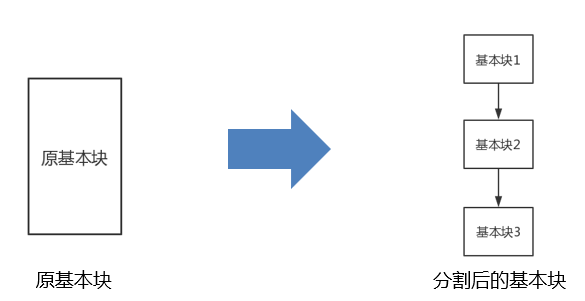
为什么要分割
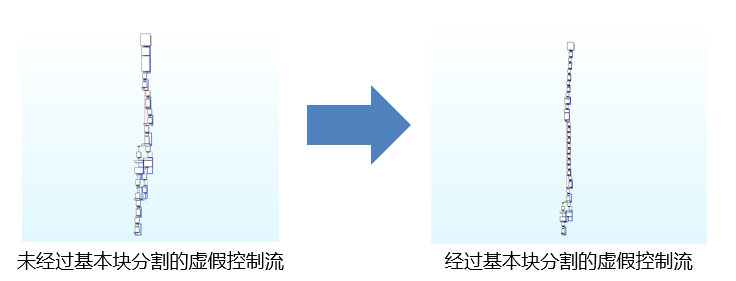
在许多基于基本块的代码混淆中,基本块数量越多,代码混淆后的复杂度越大。
通过增加基本块的数量,可以到达提高混淆效果的目的。
实现思路
遍历每个函数中的每个基本块,对每个基本块进行分割即可。
有 PHI 指令的基本块选择跳过
因为 PHI 值根据前驱块指定,分割带有 PHI 指令的基本块可能会改变其前驱块,导致带有 PHI 指令的基本块的前驱块是分割前的同一个基本块
使用到的 API
可以通过 cl::opt 模板类获取指令中的参数,这里的 opt 是选项 option 的缩写,不是优化器的意思:
1
2
3
4
5
6
7
| #include "llvm/Support/CommandLine.h"
static cl::opt<int> splitNum("split_num", cl::init(2), cl::desc("Split <split_num> time(s) each BB"));
opt -load ../Build/LLVMObfuscator.so -split -split_num 5 -S TestProgram.ll -o TestProgram_split.ll
|
splitBasicBlock 函数是 BasicBlock 类的一个成员函数。在BasicBlock.h 头文件里可以看到这个函数的两种用法:
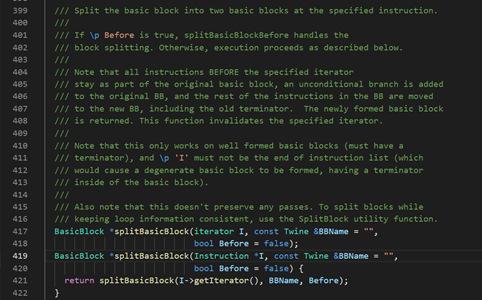
将一个基本块,在指令 I 处一分为二,指令 I 之前的指令会被放在第一个基本块里,包括指令 I 的后面指令 放到第二个基本块里,最后在第一个基本块里建立绝对跳转
有两种用法,区别在第一个参数,第一种用迭代器,第二种用指针。
第二个参数是字符串,指定分裂出来的新基本块名称。
第三个参数用于改变两个基本块的顺序,为true时,第二个基本块会放到第一个基本块之前
返回结果是指向第二个基本块(新)的指针
代码片段分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| void SplitBasicBlock::split(BasicBlock *BB){
BasicBlock *curBB = BB;
int splitSize = BB->size() / splitNum;
if(splitSize){
for(int i = 0;i < splitNum;i ++){
int cnt = 0;
for(Instruction &I : *curBB){
if(++cnt == splitSize){
curBB = curBB->splitBasicBlock(&I);
break;
}
}
}
}
}
|
isa<> 是一个模板函数,用于判断一个指针指向的数据的类型是不是给定的类型,类似于 Java 中的 instanceof
1
2
3
4
5
6
7
8
9
|
bool SplitBasicBlock::containsPHI(BasicBlock *BB){
for(Instruction &I : *BB){
if(isa<PHINode>(&I)){
return true;
}
}
return false;
}
|
代码实现
目录结构
SplitBasicBlock.cpp
引入指令参数splitNum:
1
2
|
static cl::opt<int> splitNum("split_num", cl::init(2), cl::desc("Split<split_num> time(s) each BB"));
|
SplitBasicBlock类定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| namespace{
class SplitBasicBlock : public FunctionPass{
public:
static char ID;
SplitBasicBlock() : FunctionPass(ID){
}
bool runOnFunction(Function &F);
void split(BasicBlock *BB);
bool containsPHI(BasicBlock *BB);
};
}
|
runOnFunction函数实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| bool SplitBasicBlock::runOnFunction(Function &F){
vector<BasicBlock*> origBB;
for(BasicBlock &BB : F){
origBB.push_back(&BB);
}
for(BasicBlock *BB : origBB){
if(!containsPHI(BB)){
split(BB);
}
}
return true;
}
|
为什么要先把所有基本块保存到 vector 容器中
因为要对基本块进行分割操作,分割时基本块数量会增多,所以需要把原先所有基本块保存到一个 vector 容器中,在容器中进行分裂操作不会影响 foreach 遍历
containsPHI函数实现:
1
2
3
4
5
6
7
8
| bool SplitBasicBlock::containsPHI(BasicBlock *BB){
for(Instruction &I : *BB){
if(isa<PHINode>(&I)){
return true;
}
}
return false
}
|
split函数实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| void SplitBasicBlock::split(BasicBlock *BB){
int splitSize = (BB->size() + splitNum - 1) / splitNum;
BasicBlock *curBB = BB;
for(int i = 1;i < splitNum;i++){
int cnt = 0;
for(Instruction &I : *curBB){
if(cnt++ == splitSize){
curBB = curBB->splitBasicBlock(&I);
break;
}
}
}
}
|
初始化 ID 并注册:
1
2
| char SplitBasicBlock::ID = 0;
static RegisterPass<SplitBasicBlock> x("split", "Split a basic block into multiple basic blocks.");
|
完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| #include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/IR/Instructions.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Support/CommandLine.h"
#include "../include/SplitBasicBlock.h"
#include <vector>
using std::vector;
using namespace llvm;
static cl::opt<int> splitNum("split_num", cl::init(2), cl::desc("Split<split_num> time(s) each BB"));
namespace
{
class SplitBasicBlock : public FunctionPass{
public:
static char ID;
SplitBasicBlock() : FunctionPass(ID) {}
bool runOnFunction(Function &F);
bool containsPHI(BasicBlock *BB);
void split(BasicBlock *BB);
};
}
bool SplitBasicBlock :: runOnFunction(Function &F){
vector<BasicBlock*> origBB;
for(BasicBlock &BB : F){
origBB.push_back(&BB);
}
for(BasicBlock *BB : origBB){
if(!containsPHI(BB)){
split(BB);
}
}
}
bool SplitBasicBlock::containsPHI(BasicBlock *BB){
for(Instruction &I : *BB){
if(isa<PHINode>(&I)){
return true;
}
}
return false;
}
void SplitBasicBlock::split(BasicBlock *BB){
int splitSize = (BB->size() + splitNum - 1) / splitNum;
BasicBlock *curBB = BB;
for(int i = 1;i < splitNum; i++){
int cnt = 0;
for(Instruction &I : *curBB){
if(cnt++ == splitSize){
curBB = curBB->splitBasicBlock(&I);
break;
}
}
}
}
FunctionPass* createSplitBasicBlockPass(){
return new SplitBasicBlock();
}
char SplitBasicBlock :: ID = 0;
static RegisterPass<SplitBasicBlock> x("split", "Split a basic block into multiple basic blocks.");
|
SplitBasicBlock.h
在 llvm 命名空间里添加一个函数FunctionPass* createSplitBasicBlockPass()
这个函数将在SplitBasicBlock.cpp里实现
这样的话其他 LLVM Pass 就可以通过引入头文件SplicBasicBlock.h调用createSplitBasicBlockPass函数来创建一个SplitBasicBlockPass,完成基本块的分割
1
2
3
4
5
6
| #include "llvm/IR/Function.h"
#include "llvm/Pass.h"
namespace llvm{
FunctionPass* createSplitBasicBlockPass();
}
|
在SplitBasicBlock.cpp中实现llvm::createSplitBasicBlock函数:
1
2
3
| FunctionPass* llvm::createSplitBasicBlockPass(){
return new SplitBasicBlock();
}
|
完整代码:
1
2
3
4
5
6
7
8
9
| #ifndef _SPLIT_BASIC_BLOCK_H_
#define _SPLIT_BASIC_BLOCK_H_
#include "llvm/IR/Function.h"
#include "llvm/Pass.h"
namespace llvm
{
FunctionPass* createSplitBasicBlockPass();
}
#endif
|






