Python爬虫慕课学习笔记
写在前面
不知道写啥其实说实话
网络爬虫之规则
安装requests库
cmd 命令行打开
输入pip3 install requests,等待即可
简单测试,爬一下bkjw
1 | import requests |
requests库7个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.post() | 向网页提交post请求 |
| requests.head() | 获取网页头信息 |
| requests.put() | 向网页提交put请求 |
| requests.patch() | 向网页提交局部修改请求 |
| requests.delete() | 向网页提交删除请求 |
| requests.get() | 向网页提交get请求 |
requests库其实只有一个方法——
request()方法,其他六种方法都是对request()方法的封装
requests库异常处理
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
response对象的常用属性和方法
**dir()**一个response对象可以看到它的属性和方法
1 | ['__attrs__', '__bool__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__nonzero__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_content', '_content_consumed', '_next', 'apparent_encoding', 'close', 'connection', 'content', 'cookies', 'elapsed', 'encoding', 'headers', 'history', 'is_permanent_redirect', 'is_redirect', 'iter_content', 'iter_lines', 'json', 'links', 'next', 'ok', 'raise_for_status', 'raw', 'reason', 'request', 'status_code', 'text', 'url'] |
常用的属性
| 属性 | 说明 |
|---|---|
| r.headers | HTTP响应头 |
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
| r.ok | HTTP请求成功没,返回True或False |
r.encoding:如果 header 中不存在charset,则认为编码为ISO-8859-1,不太准确
r.apparent_encoding:备选编码,从网页的内容分析编码方式,一般准确常用
r.encodint = r.apparent_encoding
通用代码框架
1 | # -*- coding: utf-8 -*- |
Requests库方法详解
重中之重:requests.request()
原型:requests.request(method,url,**kwargs)
method:对应http协议中的七种请求方法url:请求的链接**kwargs:控制访问的参数,共13个
requests.get()
原型:requests.get(url,params=None,**kwargs)
url:请求的链接params:url中的额外参数,字典或字节流格式,可选**kwargs:控制访问的参数
1 | # 传参方法一,直接在url里面拼接 |
requests.post()
原型:requests.post(url,data=None,json=None,**kwargs)
url:请求的链接data:请求的内容,可以是字典,字节序列或文件json:JSON 格式数据,也是请求的内容**kwargs:控制访问的参数
1 | # 传参方法一:直接post字典 |
data 等于一个字典的时候,用户传输的数据会被编码到 form 表单当中
而 data 直接等于一个字符串的时候,用户传输的数据会被编码到 data 里面
13个访问控制参数
**kwargs:控制访问的参数
params:字典或者字节序列,作为参数增加到url中data:字典、字节序列或文件对象,作为request的内容json: JSON 格式的数据,作为request的内容headers:字典,HTTP定制头cookies:字典或者cookiejar,作为request中的 cookieauth:元组,支持HTTP认证功能files:字典类型,传输文件timeout:设定超时时间,秒为单位,超时返回异常proxies:字典类型,设定访问代理服务器的 ip 地址,可以增加登陆认证allow_redirects:True/False,默认为True,重定向开关stream:True/False,默认为True,获取内容立即下载开关verify:True/False,默认为True,认证 SSL 证书开关cert:本地 SSL 证书路径
爬虫规则
| 爬网页 | 爬网站、系列网站 | 爬全网 |
|---|---|---|
| 小规模 | 中规模 | 大规模 |
| 爬取速度不敏感 | 爬取速度敏感 | 爬取速度关键 |
| Requests库 | Scrapy库 | 定制库 |
不要乱爬,乱爬容易出事,不然哪天就进去了
Robots协议
- 网站告知爬虫哪些页面可以爬,哪些不能爬,遵不遵守看个人
- 如果网站根目录下没有
robots.txt,则表示该网站所有东西都可以爬 类人行为可不参考Robots协议,因为其不会对服务器产生很大的影响,,但是获取的东西不能用于商业用途
网络爬虫之提取
BeautifulSoup库
- 一般引用
bs4库中的BeautifulSoup类就够了
1 | from bs4 import BeautifulSoup |

基本元素
- 标签树就是汤,
BeautifulSoup类就是将一个标签树变成一个变量,用类里面的方法来熬汤(解析标签树)
| 基本元素 | 解释 |
|---|---|
Tag |
标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
Name |
标签的名字,<p>…</p>的名字是’p’,格式:<tag>.name |
Attributes |
标签的属性,字典形式组织,格式:<tag>.attrs |
NavigableString |
标签内非属性字符串,<>…</>中字符串,格式:<tag>string |
Comment |
标签内字符串的注释部分,一种特殊的Comment类型 |
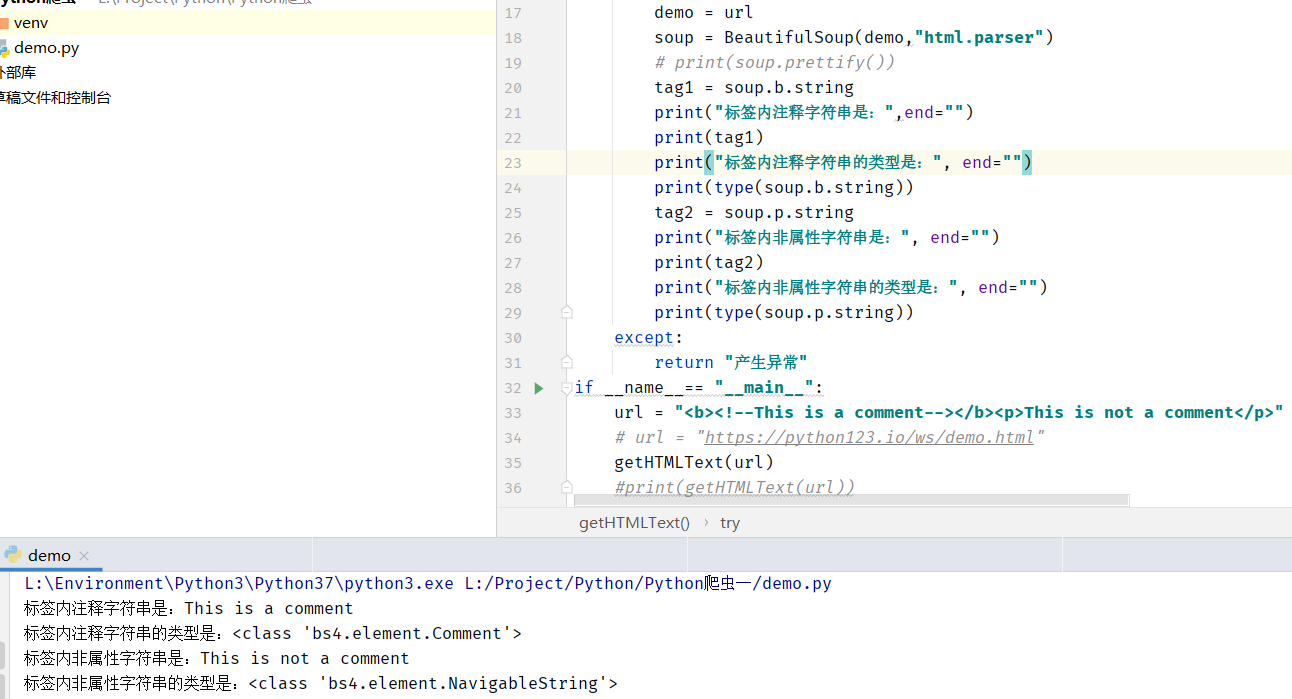
如何判断解析出来的字符串是注释还是非属性字符串?
用
type来判断,BeautifulSoup类中这两个的类型不一样
解析器
- 一共支持四种解析器
- 其中
xml和lxml需要额外安装lxml库,html5lib需要额外安装html5lib库
| 解析器 | 使用方法 | 依赖 |
|---|---|---|
bs4的HTML解析器 |
BeautifulSoup(mk,’html.parser’) | 安装bs4库 |
lxml的HTML解析器 |
BeautifulSoup(mk,’lxml’) | pip install lxml |
xml的XML解析器 |
BeautifulSoup(mk,’xml’) | pip install lxml |
html5lib的解析器 |
BeautifulSoup(mk,’html5lib’) | pip install html5lib |
基于bs4库的HTML的内容遍历方法

上行遍历
| 属性 | 说明 |
|---|---|
.parent |
节点的父亲标签 |
.parents |
节点先辈标签的迭代类型,用于循环遍历先辈节点 |
1 | for parent in soup.a.parents: |
下行遍历
| 属性 | 说明 |
|---|---|
.contents |
子节点的列表,将<tag>的所有儿子节点存入列表 |
.children |
子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
.descendants |
子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
1 | for child in soup.body.children: |
平行遍历
| 属性 | 说明 |
|---|---|
.next_sibling |
返回按照HTML文本顺序的下一个平行节点标签 |
.previous_sibling |
返回按照HTML文本顺序的上一个平行节点标签 |
.next_siblings |
迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
.previous_siblings |
迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
1 | soup.a |
1 | for sibling in soup.a.next_siblings: |
节点
- 结点不仅仅是尖括号 <> 的标签,还有一些字符内容,比如
\n或标签中未被包裹的字符串,都是节点
美化与编码
prettify()方法用于美化标签内容排版,其实就是加\n来换行,让标签树显示更加美观BeautifulSoup库对所有传入的HTML文档和字符串都解析成UTF-8编码,Python3 默认也是UTF-8编码,Python2 不是
信息组织与提取
网络爬虫之实战
Re 库入门
正则表达式语法
- 正则表达式语法由字符和操作符组成
| 操作符 | 说明 | 实例 |
|---|---|---|
. |
表示任何单个字符 | .* 表示任意字符 |
[] |
字符集,对单个字符给出取值范围 | [abc] 表示a、b、c,[a-z] 表示a到z单个字符 |
[^] |
非字符集,对单个字符给出排除范围 | [^abc] 表示非a、b、c的单个字符 |
* |
前一个字符0次或无限次扩展 | abc* 表示ab、abc、abcc、abccc等 |
+ |
前一个字符1次或无限次扩展 | abc+ 表示abc、abcc、abccc等 |
? |
前一个字符0次或1次扩展 | abc? 表示ab、abc |
| ` | ` | 左右表达式任意一个 |
{m} |
扩展前一个字符m次 | **ab{2}c **表示abbc |
{m,n} |
扩展前一个字符m至n次(含n) | **ab{1,2}c **表示abc、abbc |
^ |
匹配字符串开头 | **^abc **表示abc且在一个字符串的开头 |
$ |
匹配字符串结尾 | **abc$ **表示abc且在一个字符串的结尾 |
() |
分组标记,内部只能使用| 操作符 | (abc) 表示abc,(abc|def)表示abc、def |
\d |
数字,等价于[0‐9] | |
\w |
单词字符,等价于[A‐Za‐z0‐9_] |
- 经典举例
| re | 说明 |
|---|---|
^[A-Za-z]+$ |
由26个字母组成的字符串 |
^[A-Za-z0-9]+$ |
由26个字母和数字组成的字符串 |
^-?\d+$ |
整数形式的字符串 |
^[0-9]*[1-9][0-9]*$ |
正整数形式的字符串 |
[1-9]\d{5} |
中国境内邮政编码,6位 |
[\u4ee00-\u9fa5] |
匹配中文字符,用utf-8编码中中文字符的区间代替 |
| `\d{3}-\d{8} | \d{4}-\d{7}` |
- 非常经典的匹配 IP 地址的正则表达式
0-99:**[1-9]?\d**
100-199:1\d{2}
200-249:2[0-4]\d
250-255:25[0-5]
整合:(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
re 库基本使用
- python 的标准库,不需要额外安装
- raw string 原生字符串类型
- re 库采用原生字符串类型来表示正则表达式,形如
r'text',用 string 类型也行,但是要用转义字符来转义反斜杠,会更麻烦 - 比如:
r'[1-9]\d{5}'、r'\d{3}-\d{8}|\d{4}-\d{7}' - **raw string **是不包含转义符的字符串,转义符比如反斜杠
\
- re 库采用原生字符串类型来表示正则表达式,形如
- re 库常用功能函数
| 函数 | 说明 |
|---|---|
re.search() |
在一个字符串中搜索匹配正则表达式的第一个位置,返回 match 对象 |
re.match() |
从一个字符串的开始位置起匹配正则表达式,返回 match 对象 |
re.findall() |
搜索字符串,以列表类型返回全部能匹配到的子串 |
re.split() |
将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
re.finditer() |
搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是 match 对象 |
re.sub() |
在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
re.search(pattern,string,flags=0)
在一个字符串中搜索匹配正则表达式的第一个位置,返回 match 对象
pattern:正则表达式的字符串或原生字符串表示
string:待匹配字符串
flags:正则表达式使用时的控制标记
常用标记 说明 re.I re.IGNORECASE忽略正则表达式的大小写,[A-Z]能够匹配大小写 re.M re.MULTILINE正则表达式中的^操作符能够将给定字符串的每行当作匹配开始 re.S re.DOTALL正则表达式中的.操作符能够匹配所有字符,默认匹配是除换行以外的所有字符
1 | import re |
re.match(pattern,string,flags=0)
- ==从一个字符串的开始位置起==匹配正则表达式,返回 match 对象
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
1 | match = re.match(r'[1-9]\d{5}', 'BIT 100081') |
re.findall(pattern,string,flags=0)
- 搜索字符串,以列表类型返回全部能匹配的子串
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
1 | ls = re.findall(r'[1-9]\d{5}', 'BIT100081 TSU100084') |
re.split(pattern,string,maxsplit=0,flags=0)
- 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型,也就是将匹配到的字符串去掉,剩下的存进列表返回
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- maxsplit:最大分割数,剩余部分作为最后一个元素输出
- flags:正则表达式使用时的控制标记
1 | re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084') |
re.finditer(pattern,string,flags=0)
- 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
- pattern:正则表达式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正则表达式使用时的控制标记
1 | for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'): |
re.sub(pattern,repl, string,count=0,flags=0)
- 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
- pattern:正则表达式的字符串或原生字符串表示
- repl:替换匹配字符串的字符串
- string:待匹配字符串
- count:匹配的最大替换次数
- flags:正则表达式使用时的控制标记
1 | re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT100081 TSU100084') |
两种用法
函数式用法:一次性操作
rst = re.search(r'[1-9]\d{5}','BIT 10091')面向对象用法:将原生字符串编译成一个 re 类的对象,能够进行多次操作
pat = re.compile(r'[1-9]\d{5}')rst = pat.search('BIT 10091')re.compile(pattern,flags=0)
- 将正则表达式的字符串形式编译成正则表达式对象
- pattern:正则表达式的字符串或原生字符串表示
- flags:正则表达式使用时的控制标记
match 对象
- match 对象的属性
| 属性 | 说明 |
|---|---|
.string |
待匹配的文本 |
.re |
匹配时使用的pattern对象(正则表达式) |
.pos |
正则表达式搜索文本的开始位置 |
.endpos |
正则表达式搜索文本的结束位置 |
- match 对象的方法
| 方法 | 说明 |
|---|---|
.group(0) |
获得匹配后的字符串 |
.start() |
匹配字符串在原始字符串的开始位置 |
.end() |
匹配字符串在原始字符串的结束位置 |
.span() |
返回(.strat(),.end()) |
re 库中贪婪匹配和最小匹配
- re 库默认采用贪婪匹配,匹配最长的子串
1 | match = re.search(r'PY.*N', 'PYANBNCNDN') |
- 通过在操作符后添加 ? 可变成最小匹配
| 操作符 | 说明 |
|---|---|
*? |
前一个字符0次或无限次扩展,最小匹配 |
+? |
前一个字符1次或无限次扩展,最小匹配 |
?? |
前一个字符0次或1次扩展,最小匹配 |
{m,n}? |
扩展前一个字符m至n次(含n),最小匹配 |
网络爬虫之框架
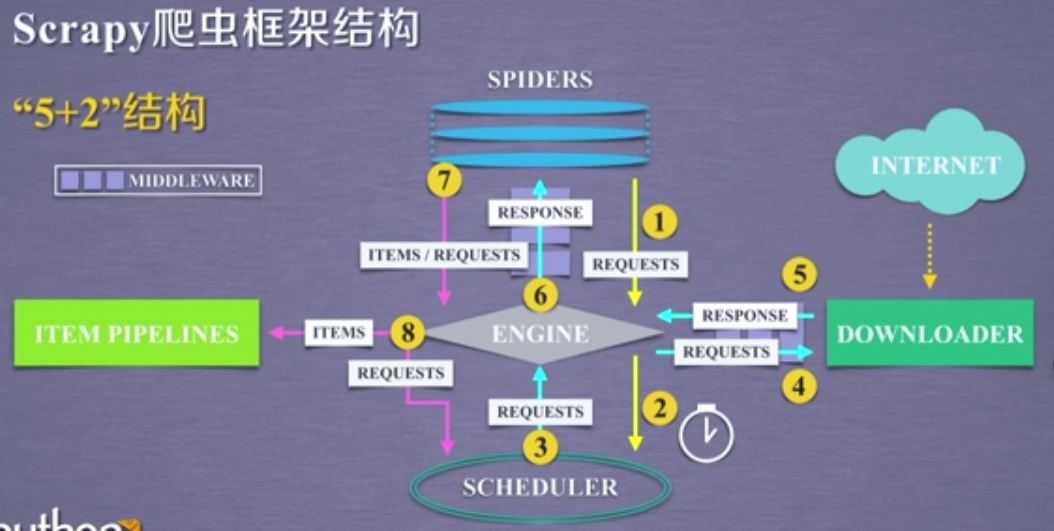
Scrapy爬虫框架
- 安装
1 | pip install scrapy |
- 框架结构(直接上图,思路很清晰)